Speeding up JSON encoding in PyPy
Hi
Recently I spent a bit of effort into speeding up JSON in PyPy. I started with writing a benchmark, which is admittedly not a very good one, but it's better than nothing (suggestions on how to improve it are welcome!).
For this particular benchmark, the numbers are as follow. Note that CPython by default uses the optimized C extension, while PyPy uses the pure Python one. PyPy trunk contains another pure Python version which has been optimized specifically for the PyPy JIT. Detailed optimizations are described later in this post.
The number reported is the time taken for the third run, when things are warmed up. Full session here.
| CPython 2.6 | 22s |
| CPython 2.7 | 3.7s |
| CPython 2.7 no C extension | 44s |
| PyPy 1.5 | 34s |
| PyPy 1.6 | 22s |
| PyPy trunk | 3.3s |
Lessons learned:
Expectations are high
A lot of performance critical stuff in Python world is already written in a hand optimized C. Writing C (especially when you interface with CPython C API) is ugly and takes significant effort. This approach does not scale well when there is a lot of code to be written or when there is a very tight coupling between the part to be rewritten and the rest of the code. Still, people would expect PyPy to be better at "tasks" and not precisely at running equivalent code, hence a comparison between the C extension and the pure python version is sound. Fortunately it's possible to outperform the C extension, but requires a bit of effort on the programmer side as well.
Often interface between the C and Python part is ugly
This is very clear if you look at json module as implemented in CPython's standard library. Not everything is in C (it would probably be just too much effort) and the interface to what is in C is guided via profiling not by what kind of interface makes sense. This especially is evident comparing CPython 2.6 to 2.7. Just adapting the code to an interface with C made the Python version slower. Removing this clutter improves the readability a lot and improves PyPy's version a bit, although I don't have hard numbers.
JitViewer is crucial
In case you're fighting with PyPy's performance, jitviewer is worth a shot. While it's not completely trivial to understand what's going on, it'll definitely show you what kind of loops got compiled and how.
No nice and fast way to build strings in Python
PyPy has a custom thing called __pypy__.builders.StringBuilder. It has a few a features that make it much easier to optimize than other ways like str.join() or cStringIO.
- You can specify the start size, which helps a lot if you can even provide a rough estimate on the size of the string (less copying)
- Only append and build are allowed. While the string is being built you can't seek or do anything else. After it's built you can never append any more.
- Unicode version available as well as __pypy__.builders.UnicodeBuilder.
Method calls are ok, immutable globals are ok
PyPy's JIT seems to be good enough for at least the simple cases. Calling methods for common infrastructure or loading globals (instead of rebinding as locals) is fast enough and improves code readability.
String copying is expensive
Edit: see the comment at the end
If you use re.sub, the current implementation will always create a copy of the string even if there was no match to replace. If you know your regexp is simple, first try to check if there is anything to replace. This is a pretty hard optimization to do automatically -- simply matching the regular expression can be too costly for it to make sense. In our particular example however, the regexp is really simple, checking ranges of characters. It also seems that this is by far the fastest way to escape characters as of now.
Generators are slower than they should be
I changed the entire thing to simply call builder.append instead of yielding to the main loop where it would be gathered. This is kind of a PyPy bug that using generators extensively is slower, but a bit hard to fix. Especially in cases where there is relatively little data being passed around (few bytes), it makes sense to gather it first. If I were to implement an efficient version of iterencode, I would probably handle chunks of predetermined size, about 1000 bytes instead of yielding data every few bytes.
I must admit I worked around PyPy's performance bug
For obscure (although eventually fixable) reasons, this:
for c in s: # s is string del c
is faster than:
for c in s: pass
This is a PyPy performance bug and should be fixed, but on a different branch ;-)
PyPy's JIT is good
I was pretty surprised, but the JIT actually did make stuff work nicely. The changes that were done were relatively minor and straightforward, once the module was cleaned to the normal "pythonic" state. It is worth noting that it's possible to write code in Python and make it run really fast, but you have to be a bit careful. Again, jitviewer is your friend when determining why things are slow. I hope we can write more tools in the future that would more automatically guide people through potential performance pitfals.
Cheers, fijal
Edit: I was wrong about re.sub. It just seems to be that the JIT is figuring match better than sub, will be fixed soon
PyPy Göteborg Post-Hallowe'en Sprint Nov 2nd - Nov 9th
The next PyPy sprint will be in Gothenburg, Sweden. It is a public sprint, suitable for newcomers. We'll focus on making a public kickoff for both the numpy/pypy integration project and the Py3k support project, as well as whatever interests the Sprint attendees. Since both of these projects are very new, there will be plenty of work suitable for newcomers to PyPy.
Other topics might include:
- Helping people get their code running with PyPy
- work on a FSCons talk?
- state of the STM Vinnova project (We most likely, but not for certain will know whether or not we are approved by this date.)
Location
The sprint will be held in the apartment of Laura Creighton and Jacob Hallén which is at Götabergsgatan 22 in Gothenburg, Sweden. Here is a map. This is in central Gothenburg. It is between the tram stops of Vasaplatsen and Valand, (a distance of 4 blocks) where many lines call -- the 2, 3, 4, 5, 7, 10 and 13.
Probably cheapest and not too far away is to book accomodation at SGS Veckobostader. The Elite Park Avenyn Hotel is a luxury hotel just a few blocks away. There are scores of hotels a short walk away from the sprint location, suitable for every budget, desire for luxury, and desire for the unusual. You could, for instance, stay on a boat. Options are too numerous to go into here. Just ask in the mailing list or on the blog.
Hours will be from 10:00 until people have had enough. It's a good idea to arrive a day before the sprint starts and leave a day later. In the middle of the sprint there usually is a break day and it's usually ok to take half-days off if you feel like it. Of course, many of you may be interested in sticking around for FSCons, held the weekend after the sprint.
Good to Know
Sweden is not part of the Euro zone. One SEK (krona in singular, kronor in plural) is roughly 1/10th of a Euro (9.36 SEK to 1 Euro).
The venue is central in Gothenburg. There is a large selection of places to get food nearby, from edible-and-cheap to outstanding. We often cook meals together, so let us know if you have any food allergies, dislikes, or special requirements.
Sweden uses the same kind of plugs as Germany. 230V AC.
Getting Here
If are coming train, you will arrive at the Central Station. It is about 12 blocks to the site from there, or you can take a tram.
There are two airports which are local to Göteborg, Landvetter (the main one) and Gothenburg City Airport (where some budget airlines fly). If you arrive at Landvetter the airport bus stops right downtown at Elite Park Avenyn Hotel which is the second stop, 4 blocks from the Sprint site, as well as the end of the line, which is the Central Station. If you arrive at Gothenburg City Airport take the bus to the end of the line. You will be at the Central Station.
You can also arrive by ferry, from either Kiel in Germany or Frederikshavn in Denmark.
Who's Coming?
If you'd like to come, please let us know when you will be arriving and leaving, as well as letting us know your interests We'll keep a list of people which we'll update (which you can do so yourself if you have bitbucket pypy commit rights).
Numpy funding and status update
Hi everyone,
It's been a little while since we wrote about NumPy on PyPy, so we wanted to give everyone an update on what we've been up to, and what's up next for us.
We would also like to note that we're launching a funding campaign for NumPy support in PyPy. Details can be found on the donation page.
Some of the things that have happened since last we wrote are:
- We added dtype support, meaning you can now create arrays of a bunch of different types, including bools, ints of a various sizes, and floats.
- More array methods and ufuncs, including things like comparison methods (==, >, etc.)
- Support for more and more argument types, for example you can index by a tuple now (only works with tuples of length one, since we only have single-dimension arrays thus far).
Some of the things we're working on at the moment:
- More dtypes, including complex values and user-defined dtypes.
- Subscripting arrays by other array as indices, and by bool arrays as masks.
- Starting to reuse Python code from the original numpy.
Some of the things on the near horizon are:
- Better support for scalar data, for example did you know that numpy.array([True], dtype=bool)[0] doesn't return a bool object? Instead it returns a numpy.bool_.
- Multi-dimensional array support.
If you're interested in helping out, we always love more contributors, Alex, Maciej, Justin, and the whole PyPy team
What is the best way to contact people about this? Our company has some interest in sponsporing this work, but it wasn't clear from this or the donations page how to actually talk to anyone about it. Maybe I'm missing the obvious.
Anonymous: The address to contact is "pypy at sfconservancy.org". Thanks!
What does it mean "Starting to reuse Python code from the original numpy"? If it is copy-paste and something will be changed in numpy git trunc, will it be automatically taken into account by your numpy for PyPy?
This is off topic but, congratulations! You already achieved Unladen Swallow's performance goal of 5x faster than cpython on average.
https://code.google.com/p/unladen-swallow/wiki/ProjectPlan#Performance
https://speed.pypy.org/
You probably have already seen that, but there is an interesting comment from Travis Oliphant about the porting of numpy to pypy :
https://technicaldiscovery.blogspot.com/2011/10/thoughts-on-porting-numpy-to-pypy.html
You haven't answered my question about reuse numpy code for 3 days, I guess because you don't know it overall. I'm not 100% agree with neither Travis opinion nor Stefan M comment from https://morepypy.blogspot.com/2011/09/py3k-for-pypy-fundraiser.html , but in answer to Stefan M you say "Since this is open source, people either work on what they like, because it's fun or scratches their itch" and "Improving the [C extensions] support is boring and frustrating". Guys, AFAIK you received FP7 support for developing some soft for users, not for fun. You should spend some efforts for boring yet important work toward the mentioned things, if you would like to obtain further increase of users number and finance support. Also, clarification about reusing CPython numpy code is also highly appreciated.
More Compact Lists with List Strategies
Since we come closer to merging the list-strategy branch I want to try to explain this memory optimization today.
Datatypes in PyPy are stored as W_<type>Objects (e.g. W_StringObject to represent strings, W_IntObject to represent ints). This is necessary due to the dynamic nature of Python. So the actual value (e.g. string, integer) is stored inside that box, resulting in an indirection. When having a large amount of such boxed objects, for example in a list, the wasted memory can become quite large.

If you have a closer look at such lists, you will see that in many of them only one type of data is stored and only few (and smaller) lists store mixed types. Another thing to observe is that those lists often won't change the types of the objects they contain at runtime very often. For instance a list of a million integers is very unlikely to suddenly get a string appended to it.
List Strategies
The goal of this work is to write an optimization that exploits this behaviour. Instead of wrapping all items in a list, we implement lists in a way that they are optimized for storing certain (primitive) datatypes. These implementations store the content of the list in unwrapped form, getting rid of the extra indirection and wrapper objects.
One approach would be to add a level of indirection, making each W_ListObject instance point to another object that stores the actual content. For this other object, several implementations would exist, for every datatype we want to store without wrapping it (as well as a general one that deals with arbitrary content). The data layout would look something like this:
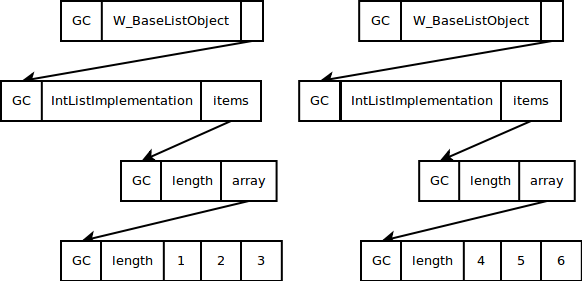
This approach has the problem that we need two indirections to get to the data and that the implementation instances need memory themselves.
What we would like to do is to make the W_ListObject point to an RPython list directly, that contains either wrapped or unwrapped data. This plan has the problem that storing different unwrapped data is not directly possible in RPython.
To solve the problem, we use the rerased RPython library module. It allows us to erase the type of an object, in this case lists, and returns something similar to void-star in C, or Object in Java. This object is then stored on the W_ListObject in the field storage. If we want to work with the list, for example to append or delete items, we need to unerase the storage again.
Example for rerase:
storage = erase([1 ,2 ,3 ,4]) # storage is an opaque object that you can do nothing with .... l = unerase(storage) l.clear()
Now that we know how to make the W_ListObject point directly to wrapped or unwrapped data, we need to find out how to actually do any operations on this data. This can be accomplished by adding another field to our W_ListObject. This field points to a ListStrategy object. The actual implementation of W_ListObject is now deferred to those ListStrategy classes. For instance, a W_ListObject which holds only integers will use the IntegerListStrategy.
When the type of content is being changed, we need to change the used strategy as well as the storage in compatible ways. For example when we add a string to the list of integers we need to switch to the ObjectListStrategy and change the storage to be a list of wrapped objects. Thus the currently used strategy always knows what to do with what is currently in the storage.

As you can see, we now save one level of indirections by storing some of the data unwrapped. Of course each operation on a list needs to go via the strategy, but since we save one indirection for each element stored in that list and the Strategy classes are singletons, the benefits outweigh the costs.
Currently there are only strategies for integers and strings since many lists seem to have these datatypes. Other strategies i.e for floats and unicode strings are planned. We also implemented two special strategies for empty lists and range-lists. The EmptyListStrategy's storage is None. If objects are added to the list we just switch to the appropriate strategy (determined by the item's type). RangeListsStrategies do not store any items at all. Instead they only store values describing the range of the list, i.e. start, step and length. On any operations that changes the data of the list we switch to the IntegerStrategy.
A nice side-effect of storing unwrapped datatypes is that we can implement optimized methods for certain cases. For instance, since comparison of unwrapped integers is now much faster than comparison between arbitrary objects, we can rewrite the sorting methods for lists containing integers.
Microbenchmarks
Finally here is an early overview of the memory consumption of different Python implementations: CPython, PyPy and PyPy-list which uses list-strategies. To demonstrate how powerful list-strategies can be in the best case, we wrote benchmarks that create a list of integers, a list of strings and a range-list each with one million elements each and then reads out the heap size of the process as reported by the OS.
The results are as follows:

The savings on integers and strings in this ideal case are quite big.
The benchmark for range-lists is a little unfair, since in CPython one could accomplish the same memory behaviour using xrange. However, in PyPy users won't notice that internally the list does not store all items, making it still possible to use all list methods, such as append or delete.
Conclusion
We hope that list strategies bring memory savings for applications that use homogeneous lists of primitive types. Furthermore, operations on such lists tend to be somewhat faster as well. This also integrates well with the JIT. The list strategies optimizations will be merged to the PyPy's default branch at some point in the next months. An equivalent optimization for dictionaries has already been merged (and is part of PyPy 1.6), one for sets is coming in the future.
Lukas Diekmann and Carl Friedrich Bolz
Nice.
But isn't there a small change in semantics to do that? If a push a python int object onto a list and then pop it back off I'll have the exact same object. But if you unwrap the object and store it as a plain int and then repop it I don't have the exact same object. I've a got a new object.
It seems to be very nice.
By the way, are object attributes optimized the same way? Objects of the same class can be expected to frequently store data of the same type in the same attribute.
I've found a nearly-year-old post on maps ( https://morepypy.blogspot.com/2010/11/efficiently-implementing-python-objects.html ), but it does not mention attribute value types... has this idea been considered?
I can see float support presenting some interesting challenges being emblematic of a wider issue. It would be very easy for someone to have a list of "floats" but if they populated it with any literals, most likely they'll be integer literals, missing any of the float optimization.
For most apps this won't be a problem but if someone is trying to optimize their application they might see this as a performance heisenbug. For example they write a hard coded list and it is slow, read it from a file and it is fast.
One approach is for there to be a document on some website (that gets out of date) that lists PyPy micro-optimizations. Someone would then need continually audit their code against that list. This doesn't seem practical.
I've seen posted some low level visualization tools. I'd be curious how practical it would be to have a higher level profiler tool integrate with the JIT to detect patterns like the list of mixed float/int situation to flag these micro-optimizations in a more automated fashion.
Winston: Indeed, very clever of you to notice :) However, we noticed as well, going forward integers (and other primitives) identity will be a function of their value, not the identity of their box. This means that for all ints `i is x` if and only if `i == x`. This also means that `id()` is now a function of value for primitives. Don't rely on that though! Just like we don't want people relying on `i is x` if `i == x and -100 < i < 200`, we don't want people relying on this either.
Anonymous:
Yes, this is definitely a consideration, I keep meaning to make time to work on this.
Well interesting, SpiderMonkey is considering to implement something like this, because NaN-boxing usually wastes a lot of memory.
@Ed I think float list can accomodate a limited set of integer values (those that can be represented correctly when interpreted as float) without any issue. You would then however need to tag which one is integer and which one is float, having to keep a bitmap. That's certainly possible, but a bit of a mess.
fijal: I think better than obscure hacks like a bitmap allowing integers as floats, perhaps it would be better just to eventually have logging of when you get fallbacks like that. For eventual integration with the jitviewer of course :)
A general runtime warning system that could say things like: "list of floats decaying to list of objects because of adding int", "two ints being compared via is", etc. might be useful. That could handle any number of situations with surprising semantics or performance.
This is very interesting. I have been thinking along somewhat similar lines for a while (but for performance reasons, rather than memory size), and so have already reviewed how I use lists in my own code. In my own programs, having non-uniform data types in a list is extremely rare. However, some lists are lists of lists (or tuples or dictionaries). The most common large lists however tend to be lists of strings.
1) If I correctly understand your explanation of what you are doing, your "list strategies" are effectively marking uniform lists as being either of one of a few known basic types (e.g. IntegerListStrategy), or just a traditional list of objects. Is that correct?
2) Do you think there are any meaningful performance optimsations which could be gained when the list type is known in advance?
3) What about built-in functions such as all(), any(), len(), min(), max(), etc? Would they be able to make use of this to improve their performance?
4) Would the underlying array data format be exposed for people who want to write extensions making direct use of it (e.g. for things like SIMD libraries)?
5) Could this allow a list to be in shared memory and directly accessed by another program?
6) Would the new list format be compatible with a "memoryview" (as str and bytearray are)?
7) My own earlier thoughts had involved marking a list as being of a uniform or non-uniform data when the list is created or altered, and using optimised code for the expected type for uniform lists. One sticky point however was threading, as a different type could be appended in another thread, which means that the consuming function would have to somehow be aware of this. Would your concept have a problem with threading if appending a string to an integer list suddenly required changing the underlying list strategy while another thread was accessing the same list?
8) Python 3.x seems to favour iterators over creating lists (e.g. map, filter, range are replaced by what used to be imap, ifilter, and xrange), and generators were introduced to complement list comprehensions in order to save memory. Does this have any implications for what you are doing?
9) Could your list concept be applied by the CPython developers to CPython? This might help ensure that any subtle semantic issues which arise as a result apply equally to CPython, rather than having people call them "Pypy bugs".
10) What about changing the Python language semantics to allow a user to specify that a list must be of a specific uniform type, and raising a type error if an element(s) of an unexpected type is added to the list? This is actually a language feature that I would like to have in order to catch errors without having to write code to examine each individual data element (as that can be slow and error prone in itself).
11) Finally, why is there such a large start-up memory use in your micro-benchmarks when comparing Pypy-list to CPython? Is this just general overhead from Pypy itself, or is that due to something related to converting the list format to a particular "list strategy"?
Anonymous: Wow a lot of questions, I'll try to answer them :)
1) Yes.
2) Probably not, you get the most performance gains when you have a large list, and if it's large the very-very-very-small initial transition is amortized over many elements.
3) Many of those are pure-python and will thus automatically gain these benefits, max() and min() unfortunately are not.
4) Probably not, we don't expose this data in any other place nor do we have any APIs for it.
5) I suppose in theory, again we have no API for it.
6) No, it wouldn't be, since that's not a part of the list API. We don't define the language, we just implement it (faster).
7) No, there's no problem with this, you simply need to lock (or whatever the equivilant in STM) is the list and do the modifications.
8) No, I don't think it does.
9) Yes, it could be applied to CPython with slightly more difficulty, and it would see the memory gains. However, it would see performance losses (as you do with teh array module on CPython) because it would need to box/unbox at every iteraction, whereas teh JIT is able to remove that.
10) Propose it to python-ideas, we don't define the language.
11) I can't understand the charts, so I can't answer this one.
Alex: I'm the anonymous with all the questions. Thank you for your detailed answers. I completely understand that there are side issues that you don't want to deal with at this time.
As for the possible performance effects of the proposed new list data format if applied to CPython, doing the operation: "y = reduce(operator.add, x, 0)" where x is either a list or array of 1,000,000 integers does not seem to produce a measurable difference in speed for me (Python 2.6 on 64 bit Ubuntu). Any differences seem to go either way when the test is repeated, so they seem equivalent within the margin of error. An equivalent for loop yields the same result (except for being slower, of course).
When extracting or replacing slices for lists and arrays (e.g. "y = x[i:i + 50]" and "x[i:i + 50] = y") within a for loop, the array version seems to be significantly *faster* than the list version for large slices (e.g. 50), and approximately the same for small slices (e.g. 5).
Theoretically, yes the implementation with array should always be slower, but I can't seem to get that result when I attempt to measure it. Perhaps I'm doing something wrong, but it appears from the (admittedly minimal) testing that I have done that significant speed penalties for CPython cannot simply be assumed.
I realize that ultimately this isn't a matter for the Pypy developers to concern themselves with, but should the question ever arise I don't think it can be dismissed out of hand.
Some additional thoughts to @Anonymous questions:
3) What about built-in functions such as all(), any(), len(), min(), max(), etc? Would they be able to make use of this to improve their performance?
len does not depend on the content of the list, so it does not win. all, any, min and max could be improved, yes.
7) My own earlier thoughts had involved marking a list as being of a uniform or non-uniform data when the list is created or altered, and using optimised code for the expected type for uniform lists. One sticky point however was threading, as a different type could be appended in another thread, which means that the consuming function would have to somehow be aware of this. Would your concept have a problem with threading if appending a string to an integer list suddenly required changing the underlying list strategy while another thread was accessing the same list?
The JIT does indeed produce special optimized code for the type of list it is currently observing, making operations faster. The fact that another thread could change the type of the list is not a problem, because we have a GIL and thus the JIT knows at which points another thread can run.
10) What about changing the Python language semantics to allow a user to specify that a list must be of a specific uniform type, and raising a type error if an element(s) of an unexpected type is added to the list? This is actually a language feature that I would like to have in order to catch errors without having to write code to examine each individual data element (as that can be slow and error prone in itself).
this already exists. it's called the array module.
11) Finally, why is there such a large start-up memory use in your micro-benchmarks when comparing Pypy-list to CPython? Is this just general overhead from Pypy itself, or is that due to something related to converting the list format to a particular "list strategy"?
The higher startup memory is also there in the PyPy without list strategies, so those have nothing to do with it.
I too had trouble understanding the chart. The vertical axis doesn't have negative numbers to represent a delta, just ignore the signs.
The blue area is an algebraically positive area, representing the startup memory use. The yellow area represents the memory use delta after doing the 1e6 items list operations.
Re list of floats-and-ints: a fully compatible way is to use the NaN-tagging idea from SpiderMonkey, i.e. have a special encoding of NaN that is normally not used, and that still leaves 32 bits of extra information. We would then represent ints in the list as such a NaN-encoded float. (At least it works as long as the integer is not too large, on 64-bit platforms.)
Neat!
Nice work people. I'm amazed it's so simple do to afterall, just switch type based on what the first element is. It must be a big boon for garbage collection, too?
The benchmark measures virtual memory (don't know on which architecture); measuring RSS would be more representative of the actual amount of RAM spent storing the data. Presumably it would also be more favourable to PyPy, since moving garbage collection doubles the amount of virtual memory.
Py3k for PyPy fundraiser
Hi,
We would like to announce a donation campaign for implementing Python 3 in PyPy.
Please read our detailed plan for all the details and donate using the
button on that page!
Thanks,
The PyPy Team
Two comments:
1. It would be really nice to see a semi-frequently updated progress bar (live is best) with # of dollars and # of contributions for the fundraising.
Part of the excitement created by sites like Kickstarter (and the Humble Indie Bundle and so on) is seeing how your small contribution adds to the whole. A donate button feels more like throwing your money into a dark hole (a very reasonable and worthwhile hole, but a hole nonetheless). Take advantage of some video game psychology and give us that "level up" feedback when we contribute! :)
2. I know you don't want to oversubscribe yourselves, but would you consider doing a similar funding drive for Numpy support? PLEASE???
Totally agree with stan about progress bar. Recent novacut's donation campaign showed importance of that a lot (since people saw that they need to hurry up with fundings and did lots of them in last couple of days).
@stan: 1. progress bar will be coming soon
2. we are actively working on putting up an equivalent page for Numpy support.
Awesome! Infact I regard Python 3 as much more important as any other features you could add now. 10% more performance is not nearly in the same league as Python3 support. Will happily spend some money on this.
For complete support thats like 200,000$. I understand it's a willing feature, but I don't think the pypy community and followers are that huge.
Btw, nice getting all the benchmarks above CPython 2.6 :)
Great work guys! I think keeping this amazing project alive is important for the Python eco-system... Here comes my $$.
I've heard that Py3K support for PyPy will be implemented in Python 2.X anyway. Is that true?
@Laurent: to be more precise, py3k will be implemented in RPython, which is indeed a subset of Python 2.
Right now we don't have any plan to port RPython to Python 3: it's not a priority and it won't give any advantage to the PyPy end users.
cpython3 is a fork of cpython2, but here you intend to support both versions with the same codebase. Does not this make the task much harder, and peeking into cpython3 code for guidance less useful? Also, isn't it possible that the resulting large set of switch (PYVERSION) {} statements will make the code less readable and maintainable?
Anyway, I have full faith in your assessment of the best approach, but I am still interested in your explanation. :)
Just made my donation. GOD SPEED.
I second stan's idea of providing a progress bar showing the overall status of the fundraising.
a) please, please get the pages lac showed in her lightning talk at pycon.uk online.
- There are pictures of people in it, and it is easier to donate to people then to something abstract
- there is text what happened
- there is text that anonymous donation is possible
b) please, work on the feedback. It is CRUCIAL to show the actual state. Giving 5€ and nothing happens is dull. Giving 5€ and a number goes up - good. Giving 500€ and a rendered bar moves a pixel - awesome!
c) I found the Python3PyPy fundraiser easily. I did not find the numpypy fundraiser. Please, put lacs pages up :) if I can vote for them somewhere, please let me know.
It's been a couple of weeks and the progress bar still isn't there. Although there is a link for it that doesn't work.
Please fix this and make it visible without having to click anything.
Hi! Please create the same kind of bucket for numpy support. I'm a big fan of Py3k, but I'm an even bigger fan of numpy - and I need it for my work. I'll donate to Py3k now, but I'll donate a bigger sum to both when I see the new bucket.
We're waiting for the final ok of the proposal so it can be said it benefits the public good. Any day now :)
* Who needs Python 3 support??? *
It looks like the PyPy project is adding things just to improve something and keep doing something but for who's sake?
I really need is proper support for C extensions. Without it, people who use Python professionally like myself, cannot switch to PyPy and we are stuck with Cython and/or Psyco.
Who steers the development of Pypy and why would these people refuse to realize what hinders thousands of developers, who would love to use Pypy to make the switch from CPython ???
Please tell me which real software projects use PyPy and for what reason they would need Py3K support!
Go ahead and add more language constructs that you can use to run academic programs even faster and keep ignoring what is really necessary to push Pypy into day-to-day usability
(* frustrated *)
Hi Stefan. There is noone who steers direction in PyPy. Since this is open source, people either work on what they like, because it's fun or scratches their itch. Note that Python 3 work is something that people expressed interest in funding -- if they fund it enough, why wouldn't developers work on it? It's more interesting than most jobs.
With regard to C extensions - it's good enough for many people, like quora to run on PyPy. Improving the support is boring and frustrating, so I don't think anyone would be willing to invest significant amount of his *free time* into that. However, feel free to speak with your money, you know how to find me.
Cheers,
fijal
Hi Maciej,
I realize that I came across in a somewhat obnoxious way. Sorry for that - I simply did not realize that PyPy is a true hobbyist project (at least currently).
I wish I could contribute funding but though I am using Python a lot at work, we are a National Lab and struggling to keep our government funding ourselves.
I hope a deep-pocket corporate will fund the Numpy development
Cheers, Stefan
Wrapping C++ Libraries with Reflection — Status Report One Year Later
Well over a year ago, work was started on the cppyy module which lives in the reflex-support branch. Since then, work has progressed at a varying pace and has included a recent sprint in Düsseldorf, last July.
Let's first take a step back and recap why we're interested in doing this, given that it is perfectly possible to use C++ through generated bindings and cpyext. cppyy makes use of reflection information generated for the C++ classes of interest, and has that reflection information available at run time. Therefore, it is able to open up complex C++ types to the JIT in a conceptually similar manner as simple types are open to it. This means that it is possible to get rid of a lot of the marshalling layers when making cross-language calls, resulting in much lower call overhead than is possible when going through the CPython API, or other methods of wrapping.
There are two problems that need to be solved: C++ language constructs need to be presented on the Python side in a natural way; and cross-language impedance mismatches need to be minimized, with some hints of the user if need be. For the former, the list of mapped features has grown to a set that is sufficient to do real work. There is now support for:
- builtin, pointer, and array types
- namespaces, classes, and inner classes
- global functions, global data
- static/instance data members and methods
- default variables, object return by value
- single and multiple (virtual) inheritance
- templated classes
- basic STL support and pythonizations
- basic (non-global) operator mapping
The second problem is harder and will always be an on-going process. But one of the more important issues has been solved at the recent Düsseldorf sprint, namely, that of reclaiming C++ objects instantiated from the Python side by the garbage collector.
Performance has also improved, especially that of the nicer "pythonized" interface that the user actually sees, although it still misses out on about a factor of 2.5 in comparison to the lower-level interface (which has gotten uglier, so you really don't want to use that). Most of this improvement is due to restructuring so that it plays nicer with the JIT and libffi, both of which themselves have seen improvements.
Work is currently concentrated on the back-ends: a CINT back-end is underway and a LLVM/CLang pre-compiled headers (PCH) back-end is planned. The latter is needed for this code to be released in the wild, rather than just used in high energy physics (HEP), as that would be easier to support. Also, within HEP, CLang's PCH are foreseen to be the future format of reflection information.
At the end of the Düsseldorf sprint, we tried a little code that did something actually "useful," namely the filling of a histogram with some random values. We did get it to work, but trying cppyy on a large class library showed that a good warning system for such things like missing classes was sorely needed. That has been added since, and revisiting the histogram example later, here is an interesting note: the pypy-c run takes 1.5x the amount of time of that of the compiled, optimized, C++ code. The run was timed start to finish, including the reflection library loading and JIT warm-up that is needed in the case of Python, but not for the compiled C++ code. However, in HEP, scientists run many short jobs while developing their analysis codes, before submitting larger jobs on the GRID to run during lunch time or overnight. Thus, a more realistic comparison is to include the compilation time needed for the C++ code and with that, the Python code needs only 55% of the time required by C++.
The choice of a programming language is often a personal one, and such arguments like the idea that C++ is hard to use typically do not carry much weight with the in-crowd that studies quantum field dynamics for fun. However, getting the prompt with your analysis results back faster is a sure winner. We hope that cppyy will soon have progressed far enough to make it useful first to particle physicists and then other uses for wrapping C++ libraries.
Wim Lavrijsen, Carl Friedrich Bolz, Armin RigoHi,
nice result. Wrapping C++ code can be even more tiresome than C, especially with large code bases. This will be a very welcome tool.
This question has probably been answered before... but I ask anyway since I couldn't find the answer.
Can the jit information be saved, so it does not need to be worked out again? Assuming all of the dependencies have not changed (.py files, pypy itself, .so files etc). Maybe if location independent code can not be saved, then trace hints or some higher level structure could be saved to inform the jit about what traces to jit? That sounds like a solution to jit warm up for code that is used repeatedly.
cu.
Hi,
thanks! :)
There was a recent thread on saving JIT information on pypy-dev:
https://mail.python.org/pipermail/pypy-dev/2011-August/008073.html
and the conclusion there was that it is too hard to be of benefit because too many parts contain addresses or calculated variables that were turned into constants.
For our (HEP) purposes, it would be of limited benefit: in the development cycle, the .py's would change all the time, and it is a safe assumption that the user codes that are being developed are the most "hot." If there is anything in the supporting code that is "hot" (most likely in the framework) it'd be in C/C++ at that point anyway.
Rather, I'd like to have an easy way of letting the user determine which portions of the code will be hot. Saving not having to run a hot loop 1000x in interpreted mode before the JIT kicks in, is going to be more valuable in scientific codes where the hot loops tend to be blatantly obvious.
Cheers,
Wim
This is great. I have been looking for just such a tool to wrap C++ numerical code.
I guess I have two questions:
1. Is there any documentation on how to use it?
2. It is very important to be able to translate between NumPy data structure and C++ data structure for me, so is there any plan to make this easy?
Thanks for great work.
Hi,
thanks! :)
ad 1) it's not at the level of being usable in a production environment. I have two known issues to resolve and probably some more unknowns. I've posted a description on pypy-dev, and I'm helping a few patient, very friendly users along. But actual documentation suggest a level of support that currently can't be offered, because all the current (and soon to disappear) caveats would need documenting as well.
ad 2) not sure what data translation you're thinking of, but in the CPython equivalent, support was added for the buffer interface and MemoryView. Those, or something similar, will be there so that numpy array's etc. can be build from return values, from public data members, and passed into function calls as arguments. Those are not translations, but rather extraction of the data pointers (which is typically intended and the most efficient, to be sure).
Cheers,
Wim
We need Software Transactional Memory
Hi all. Here is (an extract of) a short summary paper about my current position on Software Transactional Memory as a general tool in the implementation of Python or Python-like languages. Thanks to people on IRC for discussion on making this blog post better (lucian, Alex Gaynor, rguillebert, timonator, Da_Blitz). For the purpose of the present discussion, we are comparing Java with Python when it comes to multi-threading.
The problem in complex high-level languages
Like Java, the Python language gives guarantees: it is not acceptable for the Python virtual machine to crash due to incorrect usage of threads. A primitive operation in Java is something like reading or writing a field of an object; the corresponding guarantees are along the lines of: if the program reads a field of an object, and another thread writes to the same field of the same object, then the program will see either the old value, or the new value, but not something else entirely, and the virtual machine will not crash.
Higher-level languages like Python differ from Java by the fact that a "primitive operation" is far more complex. It may for example involve looking in several hash maps, perhaps doing updates. In general, it is completely impossible to map every operation that must be atomic to a single processor instruction.
Jython: fine-grained locking
This problem has been solved "explicitly" in the Jython interpreter that runs on top of Java. The solution is explicit in the following sense: throughout the Jython interpreter, every single operation makes careful use of Java-level locking mechanisms. This is an application of "fine-grained locking". For example, operations like attribute lookup, which need to perform look-ups in a number of hash maps, are protected by acquiring and releasing locks (in __getattribute__).
A draw-back of this solution is the attention to detail required. If even one place misses a lock, then there is either a bug --- and such bugs occur in cases that are increasingly rare and hard to debug as the previous bugs are fixed --- or we just file it under "differences from CPython". There is however the risk of deadlock, if two threads attempt to lock the same objects in different order.
In practice, the situation is actually not as bad as I may paint it: the number of locks in Jython is reasonable, and allows for all the "common cases" to work as expected. (For the uncommon cases, see below.)
Performance-wise, the Java virtual machine itself comes with locks that have been heavily optimized over a long period of time, so the performance is acceptable. However if this solution were coded in C, it would need a lot of extra work to optimize the locks manually (possibly introducing more of the subtle bugs).
CPython: coarse-grained locking
CPython, the standard implementation of Python in C, took a different and simpler approach: it has a single global lock, called the Global Interpreter Lock (GIL). It uses "coarse-grained locking": the lock is acquired and released around the whole execution of one bytecode (or actually a small number of bytecodes, like 100). This solution is enough to ensure that no two operations can conflict with each other, because the two bytecodes that invoke them are themselves serialized by the GIL. It is a solution which avoids --- unlike Jython --- writing careful lock-acquiring code all over the interpreter. It also offers even stronger guarantees: every bytecode runs entirely atomically.
Nowadays, the draw-back of the GIL approach is obvious on multi-core machines: by serializing the execution of bytecodes, starting multiple threads does not actually let the interpreter use of more than one core.
PyPy, the Python implementation in Python, takes the same approach so far.
Existing usage
As we have seen, we have the following situation: the existing Python language, as CPython implements it, offers very strong guarantees about multi-threaded usage. It is important to emphasize that most existing multi-threaded Python programs actually rely on such strong guarantees. This can be seen for example in a problem that takes a populated list and does in several threads:
next_item = global_list.pop()
This implicitly relies on the fact that pop() will perform atomic removal from the list. If two threads try to pop() from the same list at the same time, then the two operations will occur in one order or the other; but they will not e.g. return the same object to both threads or mess up the internal state of the list object.
With such an example in mind, it should be clear that we do not want a solution to the multi-core issue that involves dropping these strong guarantees. It is ok however to lower the barrier, as Jython does; but any Python implementation must offer some guarantees, or not offer multi-threading at all. This includes the fact that a lot of methods on built-in types are supposed to be atomic.
(It should be noted that not offering multi-threading at all is actually also a (partial) solution to the problem. Recently, several "hacks" have appeared that give a programmer more-or-less transparent access to multiple independent processes (e.g. multiprocessing). While these provide appropriate solutions in some context, they are not as widely applicable as multi-threading. As a typical example, they fail to apply when the mutiple cores need to process information that cannot be serialized at all --- a requirement for any data exchange between several processes.)
Here is an example of how Jython's consistency is weaker than CPython's GIL. It takes uncommon examples to show it, and the fact that it does not work like a CPython programmer expect them to is generally considered as an implementation detail. Consider:
Thread 1: set1.update(set2) Thread 2: set2.update(set3) Thread 3: set3.update(set1)
Each operation is atomic in the case of CPython, but decomposed in two steps (which can each be considered atomic) in the case of Jython: reading from the argument, and then updating the target set. Suppose that initially set1 = {1}, set2 = {2}, set3 = {3}. On CPython, independently on the order in which the threads run, we will end up with at least one of the sets being {1, 2, 3}. On Jython, it is possible that all three sets end up as containing two items only. The example is a bit far-fetched but should show that CPython's consistency is strictly stronger than Jython's.
PyPy
PyPy is a Python interpreter much like CPython or Jython, but the way it is produced is particular. It is an interpreter written in RPython, a subset of Python, which gets turned into a complete virtual machine (as generated C code) automatically by a step called the "translation". In this context, the trade-offs are different from the ones in CPython and in Jython: it is possible in PyPy, and even easy, to apply arbitrary whole-program transformations to the interpreter at "translation-time".
With this in mind, it is possible to imagine a whole-program transformation that would add locking on every object manipulated in RPython by the interpreter. This would end up in a situation similar to Jython. However, it would not automatically solve the issue of deadlocks, which is avoided in the case of Jython by careful manual placement of the locks. (In fact, being deadlock-free is a global program property that cannot be automatically ensured or verified; any change to Jython can in theory break this property, and thus introduce subtle deadlocks. The same applies to non-atomicity.)
In fact, we can easily check that if the interpreter accesses (for both reading and writing) objects A and B in a bytecode of thread 1, and objects B and A (in the opposite order) in a bytecode of thread 2 --- and moreover if you need to have accessed the first object before you can decide that you will need to access the second object --- then there is no way (apart from the GIL) to avoid a deadlock while keeping the strong guarantee of atomicity. Indeed, if both threads have progressed to the middle of the execution of their bytecode, then A has already been mutated by thread 1 and similarly B has already been mutated by thread 2. It is not possible to successfully continue running the threads in that case.
Using Software Transactional Memory
Software Transactional Memory (STM) is an approach that gives a solution to precisely the above problem. If a thread ended up in a situation where continuing to run it would be wrong, then we can abort and rollback. This is similar to the notion of transaction on databases. In the above example, one or both threads would notice that they are about to run into troubles and abort. This means more concretely that they need to have a way to restart execution at the start of the bytecode, with all the side-effects of what they did so far being either cancelled or just not committed yet.
We think that this capacity to abort and rollback is the missing piece of the puzzle of multi-threaded implementations of Python. Actually, according to the presentation of the problem given above, it is unavoidable that any solution that wants to offer the same level of consistency and atomicity as CPython would involve the capacity of aborting and rolling back --- which means precisely that STM cannot be avoided.
Ok, but why not settle down with Jython's approach and put careful locks left and right throughout the interpreter? Because (1) we would have to consider every operation's atomicity and make decisions (or steal Jython's) and document them here; (2) it would also be really a lot of work, to optimize these locks e.g. with the JIT as well as the JVM does; and (3) it is not the PyPy way to require manually tweaking your code everywhere for a feature that should be orthogonal. Point (3) is probably the most important here: you need to redo the work for every language you implement in PyPy. It also implies my own point (4): it is not fun :-)
In more details, the process would work as follows. (This gives an overview of one possible model; it is possible that a different model will end up being better.) In every thread:
- At the start of a bytecode, we start a "transaction". This means setting up a thread-local data structure to record a log of what occurs in the transaction.
- We record in the log all objects that are read, as well as the modifications that we would like to make.
- During this time, we detect "read" inconsistencies, shown by the object's "last-modified" timestamp being later than the start time of the current transaction, and abort. This prevents the rest of the code from running with inconsistent values.
- If we reach the end of the bytecode without a "read" inconsistency, then we atomically check for "write" inconsistencies. These are inconsistencies which arise from concurrent updates to objects in the other threads --- either our "write" objects, or our "read" objects.
- If no inconsistency is found, we "commit" the transaction by copying the delayed writes from the log into main memory.
The points at which a transaction starts or ends are exactly the points at which, in CPython, the Global Interpreter Lock is respectively acquired and released. If we ignore the fact that (purely for performance) CPython acquires and releases the GIL only every N bytecodes, then this means:
- Before any bytecode we acquire the GIL (start a transaction), and after the bytecode we release it (ends the transaction); and
- Before doing an external call to the C library or the OS we release the GIL (ends the transaction) and afterwards re-acquire it (start the next transaction).
Performance
A large number of implementation details are still open for now. From a user's point of view (i.e. the programmer using Python), the most relevant one is the overall performance impact. We cannot give precise numbers so far, and we expect the initial performance to be abysmally bad (maybe 10x slower); however, with successive improvements to the locking mechanism, to the global program transformation inserting the locks, to the garbage collector (GC), and to the Just-in-Time (JIT) compiler, we believe that it should be possible to get a roughly reasonable performance (up to maybe 2x slower). For example, the GC can maintain flags on the objects to know that they did not escape their creation thread, and do not need any logging; and the JIT compiler can aggregate several reads or writes to an object into one. We believe that these are the kind of optimizations that can give back a lot of the performance lost.
The state of STM
Transactional Memory is itself a relatively old idea, originating from a 1986 paper by Tom Knight. At first based on hardware support, the idea of software-only transactional memory (STM) was popularized in 1995 and has recently been the focus of intense research.
The approach outlined above --- using STM to form the core of the implementation of a language --- is new, as far as we know. So far, most implementations provide STM as a library feature. It requires explicit usage, often in the form of explicitly declaring which objects must be protected by STM (object-based STMs). It is only recently that native STM support has started to appear, notably in the Clojure language.
STM is described on Wikipedia as an approach that "greatly simplifies conceptual understanding of multithreaded programs and helps make programs more maintainable by working in harmony with existing high-level abstractions such as objects and modules." We actually think that these benefits are important enough to warrant being exposed to the Python programmer as well, instead of being used only internally. This would give the Python programmer a very simple interface:
with atomic:
<these operations are executed atomically>
(This is an old idea. Funny how back in 2003 people, including me, thought that this was a hack. Now I'm writing a blog post to say "it was not a hack; it's explicitly using locks that is a hack." I'm buying the idea of composability.)
From a practical point of view, I started looking seriously at the University of Rochester STM (RSTM), a C++ library that has been a focus of --- and a collection of results from --- recent research. One particularly representative paper is A Comprehensive Strategy for Contention Management in Software Transactional Memory by Michael F. Spear, Luke Dalessandro, Virendra J. Marathe and Michael L. Scott.
Conclusion
Taking these ideas and applying them in the context of an implementation of a complex high-level language like Python comes with its own challanges. In this context, using PyPy makes sense as both an experimentation platform and as a platform that is recently gaining attention for its performance. The alternatives are unattractive: doing it in CPython for example would mean globally rewriting the interpreter. In PyPy instead, we write it as a transformation that is applied systematically at translation-time. Also, PyPy is a general platform for generating fast interpreters for dynamic languages; the STM implementation in PyPy would work out of the box for other language implementations as well, instead of just for Python.
Update:
- This is mostly me (Armin Rigo) ranting aloud and trying experiments; this post should not be confused as meaning that the whole PyPy team will now spend the next years working on it full-time. As I said it is orthogonal to the actual Python interpreter, and it is in any case a feature that can be turned on or off during translation; I know that in many or most use cases, people are more interested in getting a fast PyPy rather than one which is twice as slow but scales well.
- Nothing I said is really new. For proof, see Riley and Zilles (2006) as well as Tabba (2010) who both experimented with Hardware Transactional Memory, turning CPython or PyPy interpreter's GIL into start/end transactions, as I describe here.
How to handle composability ("with atomic") when something inside composed block turns out to make a system call? With explicit locking, this shouldn't be a problem.
Re sys calls in transactions:
In clojure it is solved by requiring that code in transaction is side effect free.
You can tag code as having side effects by macro "io!" :
(defn launch-missiles
“Launch attack on remote targets with everything we have.”
[]
(io!
(doseq [missile (all-silos)]
(fire missile))))
Then if you try to execut this code in transaction clojure will complain, because you can't really rollback launching nuclear missiles :)
Ehh, I should've thought more before posting.
Code in transactions need not be side effect free - in fact in clojure side effects are the whole point of transactions. But this code should only change STM controlled variables, not outside world.
And "io!" macro is for marking code that changes things outside of STM.
Sorry for confusion.
Here are my current hacks in C, based on RSTM: https://bitbucket.org/arigo/arigo/raw/default/hack/stm/c , from the repo https://bitbucket.org/arigo/arigo .
Implementing STM at a core level is certainly a nice research topic, but I wonder whether it's the best way forward for Python.
STM works well in Haskell because it has the type system to enforce several constraints. Also most data is immutable in Haskell, so threading is mostly safe by default.
Most Python objects are mutable (by default), so users have to be very careful when using multi-threading. STM gives you a nice, composable primitive to protect your critical sections, but it does not tell where your critical sections are.
You dismiss multiprocessing because of serialization issues, but what about multiprocessing within the same process? You have a VM already, so my guess would be that it wouldn't be that hard to implement software processes (a la Erlang). Sure, using message passing may lead to a fair amount of copying, but I it seems to be much easier to implement and easier to use than shared-memory concurrency + STM.
@Thomas Schilling: I don't see how having a "multiprocessing" that uses the same process, rather than different processes, makes a difference. In both cases you need to write your threading code specially and care about explicitly transferring objects via shared memory --- either to another OS thread in the same process, or to a different process altogether.
I'm with illume... look at what Apple has done with blocks. This seems like a very efficient way forward.
Separately, you are missing something about the Java-side.
For many of the data structures in Java there are atomic and non-atomic versions. That is, when you are using a data structure on a single thread, you grab the non-atomic version. This way, you don't pay for the overhead of the locking. But, when you are sharing a data structure between threads, you use the atomic version. As a by-product of history, though it is a nice by-product, you usually get the atomic version by default. That is to say, you have to go looking for trouble by explicitly asking for the non-atomic version.
By baking this into the language, you are forcing a single policy on all programs, rather than letting the programmer choose what policy is going to be best in that scenario. Either that, or they will be forced to put code guards all over the place.
To me, it seems like the language/runtime should provide the most basic of atomic operations, and the run-time library on top should provide the policy. That's the Java approach, in a nutshell. It gives the programmer flexibility and keeps the core runtime simple and easier to optimize.
Granted, you want a high-level language where the programmer doesn't make a lot of these decisions. So... looking at your own arguments... you are expecting an initial 10x performance hit relative to the current GIL-python approach, with hopes of getting it down to 2x performance... If that's the case, why not just stick with the GIL and have Python programmers take advantage of multiprocessing by creating co-operative programs using a message passing API. In some ways, it's a little more TAUP to do it that way, isn't it?
What about replaying syscalls? Is it possible that such situation will happen?
@Anonymous: this case can be handled on a case-by-case basis (e.g. special-casing "prints" to buffer), but it also has a general solution: we turn the transaction into an "inevitable" transaction, i.e. one which cannot fail.
I already have support for this in my demo code, because it is needed to handle the cases where the nesting of the C program is such that setjmp/longjmp can no longer work. The typical example is the RETURN_VALUE bytecode. It starts a transaction, returns to the caller by popping off some C frames, then ends the transaction in the caller. When we return from the C frame of the callee, in the middle of the transaction, we notice that we won't have the setjmp around any longer, so we are not allowed to abort and rollback any more.
Inevitable transactions have the property of being "a bit like" a GIL in the sense that you can only have one in total, and other transactions cannot commit before it does. In case of the RETURN_VALUE, it's a very short transaction so it shouldn't really be a problem. For the case of a user-specified "with atomic:" block, it can make all the other threads pause. Not ideal, but at least better than nothing...
Could you explain a bit more what PyPy currently does to prevent these kinds of problems?
@Sam Wilson: as you know, the PyPy approach is to sacrifice nothing to performance for the user, and get reasonably good (if not exactly Java-level) performance anyway :-)
I should also mention generally that for some programs that I have in mind, using a message-passing API would be a complete rewrite (if it is really possible at all), whereas "just" making them multithreaded can be done. The "translate.py" of PyPy falls into this category. It is a program that heavily use objects within objects within objects in a big non-nicely-separable "mess", and I would not dare to think about how to send parts of this object graph over a messaging API and get back localized updates.
Of course there are also other use cases where you can naturally get a model that plays nicely with message passing.
@nekto0n: that's not really possible in general, because you need to have the return value of the syscall to decide what to do next, which normally means that you have to really do the syscall.
@armin please describe what will happen if 2 threads call write() on single socket object? what exactly should/will happen when iterpreter begins to dispatch CALL bytecode?
I think, it's the most questionable part of STM approach.
@nekto0n: nothing particular. The two threads will run the calls in parallel, just like CPython, which calls the send() function without any GIL acquired. What exactly occurs depends on the OS and not on the language.
I dissagree to the fact that threads whose transactions would be invalidated, are stealing CPU timeshares from other processes / threads.
STM is an 'egoist' aproach
I know this might sound stupid, but is it possible to enable/disable STM on the fly? Like to enable it only for several threads involved.
Hi,
I thought a bit about what you said about Jython. Mostly, I was thinking about a way to do this automatically instead of making it explicitly.
I came up with this first draft: https://github.com/albertz/automatic_object_locking
This will obviously also be very slow but it should be possible to optimize this well (similarly to STM). And I think it is much easier than STM.
-Albert
Funny to see how Python eats itself like an Ouroboros. Wrong design decisions that made concurrency almost impossible, dirty hacks ("dirty" compared to, for example, Erlang's approach to SMP — almost linear scalability with a number of cores with 10-20% static overhead thanks to locks) that PyPy team are trying to do to solve problems introduced by Guido's ignorance, and a lot of Python "programmers" that don't understand what SMP is. Python is a ghetto, for real.
Seems like it should be possible to guarantee performance not much worse than with a GIL.
Am I right in thinking there is a locked section where changes are written to memory? The execution before this is effectively just some speculative computation to to speed up the locked section. If it turns out there's an inconsistency, just execute the locked section as you would normally. If the speculative computation is failing most of the time or is slow, switch to not doing it -- and we are back to GIL performance.
@all: please come to the #pypy irc channel on irc.freenode.net if you want to discuss this further.
@Armin: Each in-memory process would use its own part of the heap so there would be no locking necessary except during message sending. You also don't need to have a 1-to-1 mapping of OS threads to processes. You could schedule N processes onto M OS threads (preferably chosen to match the number of CPU cores).
Of course, if you don't want a message-passing model (as you mentioned in another comment) then fine.
My argument is just that: STM is difficult to implement, difficult to make fast, and it still isn't that easy to use. A message passing model is much easier to implement and easier to use for end users. (You can still get deadlocks, but you could provide libraries for standard communication patterns which you only have to get right once, like Erlang's OTP.)
I think that there is some confusion here about what the underlying problem that you are trying to solve is.
The underlying (fundamental) problem that transactional memory as a method to replace GIL in Python is trying to solve is: automatic parallelization. That *is* hard.
Mediocre implementations of transactional memory are trivial to implement. Almost anybody can do it. Of course, the performance will be horrible.
If we stick to the idea about the underlying problem (automatic parallelization) and keep it in our minds while thinking, it is clear and utterly obvious that *any* implementation of transactional memory which is slower than serial execution is simply missing the target. The target is, obviously, to run the program faster than serial execution. Otherwise, it would be totally pointless.
Based on this reasoning, it is an *obvious* conclusion that a transactional memory implementation simply cannot be allowed to result in lower performance than serial execution of the code. Allowing lower performance would be completely irrational.
We are humans, not animals. Rationality is our distinctive feature. We have to try to follow rationality.
In light of this, saying that "It is OK for transactional memory to result in 2x slowdown" is irrational. I will write it one more time: accepting 2x slowdown is irrational.
Now, it is crucial to note that there are various kinds of performance measurements. And it is OK to slow down one performance indicator while boosting another performance indicator. For example, in web server environment, it is OK to slow down the delivery of individual web pages by a factor 1.3 - while boosting the number of requests per second by 2.3. That is *rational* and perfectly OK. Also, 3x developer productivity boost would be OK.
Following this example, if transactional memory is allowed to slow down performance of the program (compared to serial execution) by 2x, a person who follows rationally would immediately be drawn to seek for the evidence of a greater-than-2x performance boost in another area of the program.
Omitting developer productivity, how are the PyPy developers going to deliver the *mandatory* greater-than-2x performance boost (in some area) without actually solving the underlying hard problems requiring hard-core code analysis?
If PyPy's transactional memory implementation would serialize calls to the Linux kernel (because it is hard to emulate them in user-space), then this alone would prevent some programs to achieve the more-than-2x performance boost. This is because it is impossible to boost program performance (in some areas, given a particular performance indicator) unless the modified program is allowed to call kernel functions out-of-order or in parallel.
-----
Note: I am *not* saying that PyPy should give up. I am just trying to note that you do not seem to know what you are doing. But I may be wrong.
Of course the sentence "It is OK for transactional memory to result in 2x slowdown" was meant "on one thread". As soon as your program uses more than 2 threads, on a more-than-2-CPUs machine, then you win.
I read "Tabba (2010)" (Tabba: Adding Concurrency in Python Using a Commercial Processor’s Hardware Transactional Memory Support) just now.
The article:
- benchmark "iterate": This function is not making calls to other functions. The authors are independently running 16 instances of the "iterate" function on a 16-core CPU using 16 threads. The speedup in respect to unmodified CPython is 7x. The slowdown in respect to 16 CPython processes is 2.2x.
- benchmark "count": This is similar to "iterate". The speedup in respect to unmodified CPython is 4.5x. The slowdown in respect to 16 CPython processes is 3.5x.
- benchmark "pystone": This function is making calls to other functions. 16 instances of the "pystone" function on a 16-core CPU using 16 threads. The speedup in respect to unmodified CPython is 0.9x. The slowdown in respect to 16 CPython processes is 17x.
My analysis:
- iterate: The fact that N instances of this function can run in parallel without any interference can be determined easily. The algorithm to determine this is trivial. (Not to mention, the pointless loop in the function can be replaced by a NOP in a dead-code elimination pass).
- count: same as "iterate".
- pystone: It is not trivial to determine whether multiple instances can run in parallel. So, it should presumably run single-threaded.
- The article is *not* mentioning any real problem that was solved by TM in the case of "iterate", "count" or "pystone". That is logical, since the truth is that there is no real problem to solve here. The benchmark functions can be trivially run in 16 CPython Linux processes - anybody can do that (even your grandma).
My summary:
- In case of the two functions for which it *can* be trivially determined whether their instances can run in parallel, the TM approach results in a 2x-3x slowdown compared to the most basic auto-parallelization algorithm.
- In case of the function for which it *cannot* be trivially determined whether multiple instances can run in parallel, the TM approach running on 4-16 threads achieved 90% (loss of 10%) of the speed of single-threaded CPython without TM. On 1 thread, the TM approach is 2.1x slower.
Bottom line:
Call me crazy, but my conclusion from this article is that TM (at least the TM approach from the article) is not working at all.
Cool to see this happening. What's also cool is the result reported in Rossbach et al's study (https://www.neverworkintheory.org/?p=122): novices using STM did better in simple programming problems than students using traditional mechanisms, even though they thought they had done worse. "Baroque syntax" may be part of the problem; I'm sure the paper's authors would be happy to chat.
⚛, you're missing a very important bit of the paper. In it, the authors say, that the Rock hardware only holds 256 bytes of write-buffer content, while Riley and Zilles¹ determined the average write-buffer size needed for transactions to not fail prematurely would be "less than 640 bytes", which is almost three times as much as Rock offers.
Thus, the big slowdown that the pystone benchmark experiences could be caused by the shortcomings of the TM built into Rock.
I do have to agree, though, that the "benchmarks" used in the paper are not very satisfactory. However, the magical "simple parallelization algorithm" you summon in your comment would break down quite easily shortly after the complexity of the situation increases by just a bit, would it not?
¹ I only briefly glanced over the paper, so if anyone read it more thoroughly, they can feel free to correct me.
I thought Erlang successfully solved this problem years ago? And I don't think anything scales better than it. So why aren't we just copying them? Message passing, where each thread or process share absolutely nothing, is the sanest and safest way to do concurrent and multi-threaded programming. I mean, you don't even have to worry about locking! STM always seemed complicated to me.
Hardware transactional memory anyone? https://arstechnica.com/hardware/news/2011/08/ibms-new-transactional-memory-make-or-break-time-for-multithreaded-revolution.ars
@squeaky_pl: thanks for the link. In some way researching this is ultimately doomed: either transactional memory doesn't work, or it does and in 5 or 10 years all CPUs will have good hardware support and will be able to run existing software like CPython with minor changes. :-)
We are actually working on implementing this directly into stailaOS.
The high-level semantics that the Python VM provides through the GIL are perfect for most programs, and for most programmer's knowledge about concurrency.
What is the purpose of going after the GIL?
If it's just a performance boost on multiple cores, then an GIOL (global IO lock) implemented on the VM, as the GIL is, should be considered. The VM could run several OS threads blocking them on IO and releasing GIL.
If the purpose is to make concurrent programming easy and correct, it can be proven that it is not possible.
Yet, there are alternatives that don't alter the language or the semantics that can be explored.
Erlang-style message passing can be provided through object proxies implemented on top or beneath the VM, so the threads/processes can even run on different computers.
In short, an Actor model is much preferable to a shared-memory one.
https://en.wikipedia.org/wiki/Actor_model
In general, it is completely impossible to map every operation that must be atomic to a single processor instruction.Uni-source
PyPy 1.6 - kickass panda
We're pleased to announce the 1.6 release of PyPy. This release brings a lot of bugfixes and performance improvements over 1.5, and improves support for Windows 32bit and OS X 64bit. This version fully implements Python 2.7.1 and has beta level support for loading CPython C extensions. You can download it here:
https://pypy.org/download.html
What is PyPy?
PyPy is a very compliant Python interpreter, almost a drop-in replacement for CPython 2.7.1. It's fast (pypy 1.6 and cpython 2.6.2 performance comparison) due to its integrated tracing JIT compiler.
This release supports x86 machines running Linux 32/64 or Mac OS X. Windows 32 is beta (it roughly works but a lot of small issues have not been fixed so far). Windows 64 is not yet supported.
The main topics of this release are speed and stability: on average on our benchmark suite, PyPy 1.6 is between 20% and 30% faster than PyPy 1.5, which was already much faster than CPython on our set of benchmarks.
The speed improvements have been made possible by optimizing many of the layers which compose PyPy. In particular, we improved: the Garbage Collector, the JIT warmup time, the optimizations performed by the JIT, the quality of the generated machine code and the implementation of our Python interpreter.
Highlights
- Numerous performance improvements, overall giving considerable speedups:
- better GC behavior when dealing with very large objects and arrays
- fast ctypes: now calls to ctypes functions are seen and optimized by the JIT, and they are up to 60 times faster than PyPy 1.5 and 10 times faster than CPython
- improved generators(1): simple generators now are inlined into the caller loop, making performance up to 3.5 times faster than PyPy 1.5.
- improved generators(2): thanks to other optimizations, even generators that are not inlined are between 10% and 20% faster than PyPy 1.5.
- faster warmup time for the JIT
- JIT support for single floats (e.g., for array('f'))
- optimized dictionaries: the internal representation of dictionaries is now dynamically selected depending on the type of stored objects, resulting in faster code and smaller memory footprint. For example, dictionaries whose keys are all strings, or all integers. Other dictionaries are also smaller due to bugfixes.
- JitViewer: this is the first official release which includes the JitViewer, a web-based tool which helps you to see which parts of your Python code have been compiled by the JIT, down until the assembler. The jitviewer 0.1 has already been release and works well with PyPy 1.6.
- The CPython extension module API has been improved and now supports many more extensions. For information on which one are supported, please refer to our compatibility wiki.
- Multibyte encoding support: this was of of the last areas in which we were still behind CPython, but now we fully support them.
- Preliminary support for NumPy: this release includes a preview of a very fast NumPy module integrated with the PyPy JIT. Unfortunately, this does not mean that you can expect to take an existing NumPy program and run it on PyPy, because the module is still unfinished and supports only some of the numpy API. However, barring some details, what works should be blazingly fast :-)
- Bugfixes: since the 1.5 release we fixed 53 bugs in our bug tracker, not counting the numerous bugs that were found and reported through other channels than the bug tracker.
Cheers,
Hakan Ardo, Carl Friedrich Bolz, Laura Creighton, Antonio Cuni, Maciej Fijalkowski, Amaury Forgeot d'Arc, Alex Gaynor, Armin Rigo and the PyPy team
"and has beta level support for loading CPython C extensions"
does this mean that the regular Numpy and Scipy can be used with this.
no.
"Unfortunately, this does not mean that you can expect to take an existing NumPy program and run it on PyPy"
thanks for the release pypy team!
Impressive as always. Thanks for releasing such great software.
Keep up the good work.
Anghel
I did some benchmark with some simple parameterized SELECT statements, and found that pg8000 on pypy 1.6 is more than one time slower than pg8000 on python 2.7.1, while the later is already more than one time slower than psycopg2 on python 2.7.1.
Still can't build and run python-ldap extension... :(
That's a deal-breaker for me.
Congrats !!! Realy amazing job !!
By the way, where can I find more informations about the alredy implemented numpy functions ?
Thanks.
Amazing - PyPy just keeps making leaps and bounds forward for compat. and processing performance. I don't know how you guys keep up such pace, but I dig it!
How is typical memory usage these days? It's been a while since anything was reported on its resource usage vs. CPython. Maybe such a benchmark could be added to the speed site?
PyPy 1.5: 68 seconds
PyPy 1.6: 65 seconds
Python 3.2 (Intel C compiler): 36 seconds
Extrapolation to the future:
PyPy 1.17: 35 seconds ?
Jokes aside, PyPy's compatibility with CPython is good.
I'm still most looking forward to the day your jit makes some .pyj files. Initialization time for the jit is a bit high, especially if you use pypy integrated into other scripts where the init time might impact performance, numpy had no dtypes, and laked almost every function, but atleast it's a step in the right direction :)
Memory usage for one of my own test apps (building a one dimensional dict with int keys, and object (sometimes by reference from a second dict) resulted in 76MB to python2.7 and 108MB to pypy 1.6. So memory usage is still a bit behind tho (the pypy runtime was better with around 35% tho).
Is there a 32-bit OSX version somewhere? 64-bit seems to eat up memory in my tests...
Impressive stuff, though :-)
But man! What's wrong with Windows?
Will the windows version will be dropped?
Version 1.5 does not fully work on Windows and now you release 1.6 you does not provide a windows version...
So, I really want to know if it will be future support for windows.
This will help to decide if pypy will be an option or one just have to find other options to speed up the programs.
Please, clarify this.
Bests,
Pypy does support Windows 32bit, with a couple of bugs, the windows support have been improved from 1.5 to 1.6. Perhaps it will be fully working by 1.7.
Visualization of JITted code
Hello.
We're proud to announce the first public release of the jitviewer. As of now, jitviewer is a slightly internal tool that helps understanding how your Python source code is compiled by the PyPy's JIT all the way down to machine code.
To install it, you need a very recent version of PyPy (newer than 9th of August), for example one of the nightly builds:
- install pip and distribute either by creating a PyPy virtualenv or by following the installation instructions.
- make sure to have a source code checkout of PyPy and put it in your PYTHONPATH.
- pip install jitviewer. Note that you need to run the pip executable which belongs to PyPy, not the globally installed one.
Have a look at the README for how to start it, or try the online demo if you just want to play with it.
The jitviewer is a web application written with flask and jinja2. If you have experience with web development and you want to help PyPy, don't hesitate to contact us, there are plenty of things to improve in it :-).
What does the jitviewer really do?
At the top of the page, you will see the list of pieces of code which has been compiled by the JIT. You will see entries for both normal loops and for "entry bridges". This is not the right place to discuss the difference between those, but you most probably want to look at loops, because usually it's where most of the time is spent.
Note that for each loop, you will see the name of the function which contains the first instruction of the loop. However, thanks to the inlining done by the JIT, it will contain also the code for other functions.
Once you select a loop, the jitviewer shows how the JIT has compiled the Python source code into assembler in a hierarchical way. It displays four levels:
-
Python source code: only the lines shown in azure have been compiled for this particular loop, the ones in gray have not.
-
Python bytecode, the one you would get by doing:
def f(a, b): return a + b import dis dis.dis(f)
The opcodes are e.g. LOAD_FAST, LOAD_GLOBAL etc. The opcodes which are not in bold have been completely optimized aways by the JIT.
-
Intermediate representation of jit code (IR). This is a combination of operations (like integer addition, reading fields out of structures) and guards (which check that the assumptions we made are actually true). Guards are in red. These operations are "at the same level as C": so, for example, + takes two unboxed integers which can be stored into the register of the CPU.
-
Assembler: you can see it by clicking on "Show assembler" in the menu on the right.
Sometimes you'll find that a guard fails often enough that a new piece of assembler is required to be compiled. This is an alternative path through the code and it's called a bridge. You can see bridges in the jitviewer when there is a link next to a guard. For more information about purpose look up the jit documentation.
I'm still confused
Jitviewer is not perfect when it comes to explaining what's going on. Feel free to pop up on IRC or send us a mail to the mailing list, we'll try to explain and/or improve the situation. Consult the contact page for details.
Cheers,
fijal & antocuni
I'm getting a TemplateNotFound jinja2 exception when I run the jitviewer.py as shown in the README.
I think you have to python setup.py install it in a virtualenv. It might not work from the checkout any more.
Would it be possible to get some screenshots of jitviewer, as the online demo is currently down?
The demo doesn't work
Please, could you put it back?
Thanks a lot!
I'm developing a programming languaje based on mindmaps and I would like to know if my code works with pypy...
PyPy is faster than C, again: string formatting
String formatting is probably something you do just about every day in Python, and never think about. It's so easy, just "%d %d" % (i, i) and you're done. No thinking about how to size your result buffer, whether your output has an appropriate NULL byte at the end, or any other details. A C equivalent might be:
char x[44]; sprintf(x, "%d %d", i, i);
Note that we had to stop for a second and consider how big numbers might get and overestimate the size (44 = length of the biggest number on 64bit (20) + 1 for the sign * 2 + 1 (for the space) + 1 (NUL byte)), it took the authors of this post, fijal and alex, 3 tries to get the math right on this :-)
This is fine, except you can't even return x from this function, a more fair comparison might be:
char *x = malloc(44 * sizeof(char)); sprintf(x, "%d %d", i, i);
x is slightly overallocated in some situations, but that's fine.
But we're not here to just discuss the implementation of string formatting, we're here to discuss how blazing fast PyPy is at it, with the new unroll-if-alt branch. Given the Python code:
def main():
for i in xrange(10000000):
"%d %d" % (i, i)
main()
and the C code:
#include <stdio.h>
#include <stdlib.h>
int main() {
int i = 0;
char x[44];
for (i = 0; i < 10000000; i++) {
sprintf(x, "%d %d", i, i);
}
}
Run under PyPy, at the head of the unroll-if-alt branch, and compiled with GCC 4.5.2 at -O4 (other optimization levels were tested, this produced the best performance). It took 0.85 seconds to execute under PyPy, and 1.63 seconds with the compiled binary. We think this demonstrates the incredible potential of dynamic compilation, GCC is unable to inline or unroll the sprintf call, because it sits inside of libc.
Benchmarking the C code:
#include <stdio.h>
#include <stdlib.h>
int main() {
int i = 0;
for (i = 0; i < 10000000; i++) {
char *x = malloc(44 * sizeof(char));
sprintf(x, "%d %d", i, i);
free(x);
}
}
Which as discussed above, is more comperable to the Python, gives a result of 1.96 seconds.
Summary of performance:
| Platform | GCC (stack) | GCC (malloc) | CPython | PyPy (unroll-if-alt) |
| Time | 1.63s | 1.96s | 10.2s | 0.85s |
| relative to C | 1x | 0.83x | 0.16x | 1.9x |
Overall PyPy is almost 2x faster. This is clearly win for dynamic compilation over static - the sprintf function lives in libc and so cannot be specializing over the constant string, which has to be parsed every time it's executed. In the case of PyPy, we specialize the assembler if we detect the left hand string of the modulo operator to be constant.
Cheers,
alex & fijal
Are you sure the compiler isn't optimizing away the actual execution since you're not doing anything with the result?
How are those two loops equivalent? You're not printing anything in the Python loop. I/O buffering etc. can eat quite a bit of runtime. It would also be nice to see what the particular improvements in this "unroll-if-alt" branch are.
How about doing something like that:
....
char p[5] = "%d %d"
//and then
sprintf(x, p, i,i);
....
?
@Thomas the C one doesn't print anything, either; sprintf just returns a string. printf is the one that prints.
@Thomas the C one doesn't print anything either, so it sounds pretty equivalent to me.
This doesn't really have anything to do with dynamic compilation, but cross module optimization. There are static compilers, such as the Glasgow Haskell Compiler, that do this. If the compilation strategy depended on runtime data (e.g. measure hot spots), it would be dynamic compilation.
*yawn* If you want to see ridiculously fast string formatting, look at the Boost's Spirit library (specifically Karma). Small test case, but point well illustrated: https://www.boost.org/doc/libs/1_47_0/libs/spirit/doc/html/spirit/karma/performance_measurements/numeric_performance/int_performance.html Or look at Spirit's input parser for even integers: https://alexott.blogspot.com/2010/01/boostspirit2-vs-atoi.html
@JoeHillen: the unroll-if-alt branch is inside the main pypy repo on bitbucket (together with all the other branches).
@Greg: yes, we checked the generated code, it's not optimized away.
@anonymous: why it should be any faster? String literals in C are constants, it's not that you need to create a new one at each iteration
@Johan: note that the PyPy approach can generate code optimized for a formatting string loaded from a disk, or computed at runtime. No static compiler could do that.
What machine are you on that an int is 64 bits? Hardly anybody uses ILP64 or SILP64 data models ( https://en.wikipedia.org/wiki/64-bit#Specific_C-language_data_models ). Maybe a fourth try is in order? :P
So when are you going to teach PyPy that the result of an unused string formatting can be deleted, and then delete the loop? ;)
I'm not sure how you'd get there from a tracing JIT, though. WIth Python, you still have to call all the formatting and stringification methods because they might have side effects. You only get to know that the entire operation is a no-op after you've inlined everything, but by then it will be at a low enough representation that it's hard to tell.
sizeof(char)==1. By definition. Argh.
PS: negative karma for lying headline
Check that you're not spending all your time in malloc/free(). Also use the return value from a failed snprintf(), plus 1, to size your output buffer.
@Anonymous 2: Even if all the time were spent in malloc/free, PyPy has to dynamically allocate the string data structure, as well as provide a buffer to fill with the characters from the integers, since it has no way of knowing how much space will be needed (could be a custom integer class).
However, you're right that malloc and free are slow and a good gc system would have a faster allocator.
a quick tip to minimize the math in determining your sprintf buffer size for your experiment:
#include < stdint.h >
len = snprintf(NULL, 0, "%d %d", INT32_MIN, INT32_MIN);
will give you the string length required (not including null terminating byte) to fit the formatted string.
Similarly, %lld and INT64_MIN will do the trick (on the right platform) for 64-bit signed integers.
(not that I advocate fixed sized buffers for formatted strings based on min/max digit lengths for any real application)
You wrote:
and compiled with GCC 4.5.2 at -O4
Please read the manual of GCC. There you will see that every optimization level above 3 is handled as it would be 3. '-O4' is nothing else than '-O3'.
It is also known that optimizing with -O3 may lead to several problems at runtime (e.g. memory delays for short programs or memory allocation failure in larger programs).
That's why the recommended optimization level is '2' (or 's' for embedded systems) and not '3'.
Did you test with a realtime kernel?
How about the scheduler?
Maybe you should double check your test environment.
For all you complaining about test eviorment. Pypy would still have to do that internaly. If they should be truely comparable, then you need to also include snprintf inside the loop, making C even slower. Also, I doubt you will get 200% performance boost from scheduler change.
unroll-if-alt will be included in 1.6 right? Also when will 1.6 be released?
@Andrew, @hobbs: Oh, sorry I overlooked the "s" in "sprintf". It would still be nice compare the generated machine code to explain the differences.
Whenever, someone claims language L1 implementation A is faster than language L2 implementation B there are obvious questions about (1) fairness of comparison, (2) what is being measured. In this case PyPy is specializing on the format string interpreter (does that require library annotations?) which a C compiler could do in principle here (but probably doesn't.) So, I'm always a bit suspicious when I see these kinds of comparisons.
@Johan: GHC's cross-module optimization often comes at the expense of binary compatibility. A JIT has a big advantage here.
The python faster than C day has come! Congrats.
ps. Did you try it with (Link Time Optimization)LTO? that is with gcc the option: -flto ? Also, are you using PGO with gcc?
@salmon According to this commit new style formatting is supported too.
Someone correct me if I'm wrong.
I think that computation is not correct yet. IIRC, you only get 20 digits in an unsigned 64-bit quantity.
Worse, (again IIRC) sprintf is locale dependent. It may insert thousands separators.
This is not a good performance test because all printf function have high constant complexity, without looking at format string, check it
wouldn't it be better to run your test with a more modern c++ library like cstring?
post the Assembly code, map files and call graph or it didnt happen!!!!!!!!
What performance impact does the malloc/free produce in the C code? AFAIK Python allocates memory in larger chunks from the operating system. Probably Python does not have to call malloc after initialization after it allocated the first chunk.
AFAIK each malloc/free crosses the boundaries between user-mode/kernel-mode.
So, IMHO you should compare the numbers of a C program which
does not allocate dynamic memory more than once and uses an internal memory management system.
These numbers would be interesting.
Have fun
The point here is not that the Python implementation of formatting is better than the C standard library, but that dynamic optimisation can make a big difference. The first time the formatting operator is called its format string is parsed and assembly code for assembling the output generated. The next 999999 times that assembly code is used without doing the parsing step. Even if sprintf were defined locally, a static compiler can’t optimise away the parsing step, so that work is done redundantly every time around the loop.
In a language like Haskell something similar happens. A string formatting function in the style of sprintf would take a format string as a parameter and return a new function that formats its arguments according to that string. The new function corresponds to the specialized assembly code generated by PyPy’s JIT. I think if you wanted to give the static compiler the opportunity to do optimizations that PyPy does at runtime you would need to use a custom type rather than a string as the formatting spec. (NB my knowledge of functional-language implementation is 20 years out of date so take the above with a pinch of salt.)
@Anonymous:
The C code shown does not do any malloc/free. The sprintf function formats the string into the char array x, which is allocated on the stack. It is highly unlikely that the sprintf function itself mallocs any memory.
I'm following the progress on pypy since many years and the potential is and has always been here. And boy, pypy has come a looong way.
You are my favorite open-source project and I am excited to see what will happen next. Go pypy-team, go!
You wrote: "We think this demonstrates the incredible potential of dynamic compilation, ..."
I disagree. You tested a microbenchmark. Claims about compiler or language X winning over Y should be made after observing patterns in real programs. That is: execute or analyse real C programs which are making use of 'sprintf', record their use of 'sprintf', create a statistics out of the recorded data and then finally use the statistical distributions to create Python programs with a similar distribution of calls to '%'.
Trivial microbenchmarks can be deceiving.
@Dave Kirby:
There are two C programs there. One on the stack, one with a malloc / free in the loop.
Which one is used for the faster claim?
@Anonymous: this branch, unroll-if-alt, will not be included in the release 1.6, which we're doing right now (it should be out any day now). It will only be included in the next release, which we hope to do soonish. It will also be in the nightly builds as soon as it is merged.
Is string/IO performance in general being worked on in Pypy? Last I looked Pypy showed it was faster than CPython in many cases on its benchmarks page, but for many string/IO intensive tasks I tried Pypy v1.5 on, it was slower.
@Connelly yes, for some definition of working (being thought about). that's one reason why twisted_tcp is slower than other twisted benchmarks. We however welcome simple benchmarks as bugs on the issue tracker
This is a horribly flawed benchmark which illustrates absolutely nothing. First of all, an optimizing JIT should be (easily) able to detect that your inner loop has no side effects and optimize it away. Secondly, with code like that you should expect all kinds of weirds transformations by the compiler, hence - you can't be really sure what you are comparing here. As many here have pointed out, you should compare the output assembly.
Anyway, if you really want to do a benchmark like that, do it the right way. Make the loop grow a string by continuous appending and write the string to the file in the end (time the loop only). This way you will get accurate results which really compare the performance of two compilers performing the same task.
try in nodejs:
var t = (new Date()).getTime();
function main() {
var x;
for (var i = 0; i < 10000000; i++)
x = i + " " + i;
return x;
}
x = main();
t = (new Date()).getTime() - t;
console.log(x + ", " + t);
I have now put a small, slightly more realistic benchmark. I used following code.
Python
def main():
x = ""
for i in xrange(50000):
x = "%s %d" % (x, i)
return x
x = main()
f = open("log.txt", "w")
f.write(x)
f.close()
C
#include
#include
#include
int main() {
int i;
char *x = malloc(0);
FILE *file;
*x = 0x00;
for (i = 0; i < 50000; i++) {
char *nx = malloc(strlen(x) + 16); // +16 bytes to be on the safe side
sprintf(nx, "%s %d", x, i);
free(x);
x = nx;
}
file = fopen("log1.txt","w");
fprintf(file, "%s", x);
fclose(file);
}
JavaScript (NodeJS)
var fs = require('fs');
String.prototype.format = function() {
var formatted = this;
for (var i = 0; i < arguments.length; i++) {
var regexp = new RegExp('\\{'+i+'\\}', 'gi');
formatted = formatted.replace(regexp, arguments[i]);
}
return formatted;
};
function main() {
var x = "";
for (var i = 0; i < 50000; i++)
x = "{0} {1}".format(x, i);
return(x)
}
x = main();
fs.writeFile('log.txt', x)
Note for JS example: I did not want to use the stuff like i + " " + i because it bypasses the format function call. Obviously, using the + operator the nodejs example would be much faster (but pypy probably as well).
Also, I used PyPy 1.5 as I did not find any precompiled PyPy 1.6 for OS X.
Results:
PyPy: real 0m13.307s
NodeJS: real 0m44.350s
C: real 0m1.812s
@tt: This is a very inefficient C/C++ implementation of the idea "make a loop grow a string by continuous appending and write the string to the file in the end". In addition, it appears to be an uncommon piece of C/C++ code.
Well, I never said anything about writing super efficient C code. Anyway, I don't see how you want to implement string formatting more efficiently - if we talk about general usage scenario. You can't really reuse the old string buffer, you basically have to allocate new one each time the string grows. Or pre-allocate a larger string buffer and do some substring copies (which will result in a much more complicated code). Anyway, the malloc() on OS X is very fast.
My point is: even this C code, which you call inefficient is around 6 times faster then pypy 1.5
@tt except one of the main points of the post was that they had implemented a *new* feature (unroll-if-alt, I believe) that sped things up a bunch.
I'm not sure how much any comparison that *doesn't* use this new feature is worth ...
So many haters ! ;)
The compare is good because both use standard langauge fetatures to do the same thing, using a third part lib is not the same, then I have to code the same implant in RPython and people would still complain do to RPython often being faster then C regardless.
Python could have detected that the loop is not doing anything, but give that one value had a __str__ call it could've broken some code. Anyway, C compiler could also see that you didn't do anything with the value and optimalize it the same way.
@Antiplutocrat:
Honestly, I expected a bit more objectivity from posters here. I am really disappointed that you compare me to "haters" (whoever that may be).
Your point about unroll-if-alt is absolutely valid and I myself have explicitly stated that I did not use that feature. At no point I have refuted that the original blog post was wrong - it is still very well possible that PyPy 1.6 is faster then C in this usage scenario. The main goal of my post was to make clear that the original benchmarks were flawed, as they grant the compiler too much space for unpredictable optimizations. I believe that my benchmark code produces more realistic results and I suggest that the authors of this blog entry re-run the benchmark using my code (or something similar, which controls for unpredictable optimizations).
Only a quick note OffTopic: in the python FAQ, one could update adding PyPy besides Psyco in the performance tips:
https://docs.python.org/faq/programming.html#my-program-is-too-slow-how-do-i-speed-it-up
@Anonymous: I agree with your other paragraphs, but not with the one where you wrote that "... OLDER version (4.5.x) of GCC whilst a newer version (4.6.x) is available with major improvements to the optimizer in general".
I am not sure, what "major improvements" in GCC 4.6 do you mean? Do you have benchmark numbers to back up your claim?
As far as well-written C code is concerned, in my opinion, there haven't been any "major improvements" in GCC for more than 5+ years. There have been improvements of a few percent in a limited number of cases - but nothing major.
Even LTO (link-time optimization (and lets hope it will be safe/stable to use when GCC 4.7 is released)) isn't a major boost. I haven't seen LTO being able to optimize calls to functions living in dynamic libraries (the bsearch(3) function would be a nice candidate). And I also haven't seen GCC's LTO being able to optimize calls to/within the Qt GUI library when painting pixels or lines onto the screen.
The main point of the PyPy article was that run-time optimizations in PyPy have a chance of surpassing GCC in certain cases.
Personally, I probably wouldn't willingly choose to work on a project like PyPy - since, err, I believe that hard-core JIT optimizations on a dynamically typed language like Python are generally a bad idea - but I am (in a positive way) eager to see what the PyPy team will be able to do in this field in the years to come.
@⚛: I indeed do not have benchmarks for these claims, but GCC 4.6 indeed added some newer optimization techniques to its assortment. Maybe these may not have had a significant influence in said case but they might have somewhere else. I'm merely saying: you can't really compare the latest hot inventions with something that is surpassed (e.g. compare Java 7 to a program output by Visual C++ back form the VS 2003 IDE).
All by all, I'm not saying that Python sucks and don't want to sound like a fanboy (on the contrary, Linux uses a great deal of Python and if this could mean a major speedup, then why the hell not ;).
I guess I was pissed off because the written article sounds very much fanboyish and pro-Python (just look at the title alone).
So a loop that doesn't print in Python is compared to a loop in C that does and that was compiled on one of the slowest C compilers out there.
YearOfTheLinuxDesktopIsAtHand(TM)
It would be neat to get UnicodeBuilder and StringBuilder in to mainline Python. They'd be more efficient in CPython than existing string construction methods and it would be easier to write more performant portable Python.
Can you elaborate a bit on the slowness of generators?
Ian: yes it would, python-ideas/dev has had this discussion many times, if you want to convince them of the merit of this idea, feel free to try, but I've gotten weary of this discussion
This is not meant to derail the rather nice performance numbers, but I wouldn't call the json/simplejson code "pythonic" in the first place.
I wonder if using a constant object to dump in each iteration doesn't skew the benchmark in favor of pypy, whereas the jit couldn't optimize as much with a varying object (which is what usually happens in real-life scenarios).
@Gaetan it certainly could in theory. In practice it does not occur here, but I only know that from looking at traces. However, creating a new object each time would make the benchmark more of an object creation one (probably GC related)
@Maciej: not if you build the list of objects to dump out of the timed loop, or did I miss something?
True, that might be a bit biggish though. Anyway as I said, it's good enough, JIT does not assume such things are constant. In fact it would execute exactly the same code for similarily shaped objects (different if all objects slightly differ in shape though)
Interfacing Python to C isn't ugly if you use Cython.
That is probably a matter of taste which we should not discuss among gentleman, I however find pure python better than Python-Cython-C combination. Also parsing JSON in C is not fun at all.
The guys from ultrajson have a benchmark here https://github.com/esnme/ultrajson/blob/master/python/benchmark.py
and the results are in the README https://github.com/esnme/ultrajson/blob/master/README
would be interesting to run those benchmarks (of course, first warming up the jit), and comparing the results to ultrajson.
feel free leonardo :)
It was just a suggestion on how to improve it, like you asked. If it was just going to be ignored I would not have bothered.