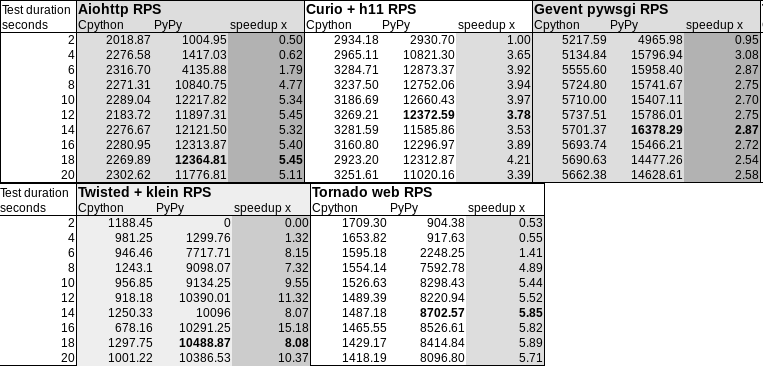
Async HTTP benchmarks on PyPy3

Leysin Winter Sprint: 25/26th Feb. - 4th March 2017
The next PyPy sprint will be in Leysin, Switzerland, for the twelveth time. This is a fully public sprint: newcomers and topics other than those proposed below are welcome.
Goals and topics of the sprint
The list of topics is very open.
- The main topic is Python 3.5 support in PyPy, as most py3.5 contributors should be present. It is also a good topic if you have no or limited experience with PyPy contribution: we can easily find something semi-independent that is not done in py3.5 so far, and do pair-programming with you.
- Any other topic is fine too: JIT compiler optimizations, CFFI, the RevDB reverse debugger, improving to speed of your program on PyPy, etc.
- And as usual, the main side goal is to have fun in winter sports :-) We can take a day off (for ski or anything else).
Exact times
Work days: starting 26th Feb (~noon), ending March 4th (~noon).
I have pre-booked the week from Saturday Feb 25th to Saturday March 4th. If it is possible for you to arrive Sunday before mid-afternoon, then you should get a booking from Sunday only. The break day should be around Wednesday.
It is fine to stay a few more days on either side, or conversely to book for a part of that time only.
Location & Accomodation
Leysin, Switzerland, "same place as before".

Let me refresh your memory: both the sprint venue and the lodging will be in a pair of chalets built specifically for bed & breakfast: https://www.ermina.ch/. The place has a good ADSL Internet connection with wireless installed. You can also arrange your own lodging elsewhere (as long as you are in Leysin, you cannot be more than a 15 minutes walk away from the sprint venue).
Please confirm that you are coming so that we can adjust the reservations as appropriate.
The options of rooms are a bit more limited than on previous years because the place for bed-and-breakfast is shrinking; but we should still have enough room for us. The price is around 60 CHF, breakfast included, in shared rooms (3 or 4 people). If there are people that would prefer a double or single room, please contact me and we'll see what choices you have. There are also a choice of hotels in Leysin.
Please register by Mercurial:
https://bitbucket.org/pypy/extradoc/ https://foss.heptapod.net/pypy/extradoc/-/blob/branch/default/extradoc/sprintinfo/leysin-winter-2017/
or on the pypy-dev mailing list if you do not yet have check-in rights:
https://mail.python.org/mailman/listinfo/pypy-dev
You need a Swiss-to-(insert country here) power adapter. There will be some Swiss-to-EU adapters around, and at least one EU-format power strip.
PyPy2.7 v5.6 released - stdlib 2.7.12 support, C-API improvements, and more
We have released PyPy2.7 v5.6 [0], about two months after PyPy2.7 v5.4. This new PyPy2.7 release includes the upstream stdlib version 2.7.12.
We continue to make incremental improvements to our C-API compatibility layer (cpyext). We pass all but 12 of the over-6000 tests in the upstream NumPy test suite, and have begun examining what it would take to support Pandas and PyQt.
Work proceeds at a good pace on the PyPy3.5 version due to a grant from the Mozilla Foundation, and some of those changes have been backported to PyPy2.7 where relevant.
The PowerPC and s390x backend have been enhanced with the capability to use SIMD instructions for micronumpy loops.
We changed
timeit to now report average +/- standard deviation, which is better than the misleading minimum value reported in CPython.We now support building PyPy with OpenSSL 1.1 in our built-in _ssl module, as well as maintaining support for previous versions.
CFFI has been updated to 1.9, improving an already great package for interfacing with C.
As always, this release fixed many issues and bugs raised by the growing community of PyPy users. We strongly recommend updating. You can download the PyPy2.7 v5.6 release here:
Downstream packagers have been hard at work. The Debian package is already available, and the portable PyPy versions are also ready, for those who wish to run PyPy on other Linux distributions like RHEL/Centos 5.
We would like to thank our donors for the continued support of the PyPy project.
We would also like to thank our contributors and encourage new people to join the project. PyPy has many layers and we need help with all of them: PyPy and RPython documentation improvements, tweaking popular modules to run on pypy, or general help with making RPython’s JIT even better.
What is PyPy?
PyPy is a very compliant Python interpreter, almost a drop-in replacement for CPython 2.7. It’s fast (PyPy and CPython 2.7.x performance comparison) due to its integrated tracing JIT compiler.We also welcome developers of other dynamic languages to see what RPython can do for them.
This release supports:
- x86 machines on most common operating systems (Linux 32/64 bits, Mac OS X 64 bits, Windows 32 bits, OpenBSD, FreeBSD)
- newer ARM hardware (ARMv6 or ARMv7, with VFPv3) running Linux,
- big- and little-endian variants of PPC64 running Linux,
- s390x running Linux
What else is new?
Cheers, The PyPy team
[0] We skipped 5.5 since we share a code base with PyPy3, and PyPy3.3-v.5.5-alpha was released last month
I am really liking the regular updates! Nice to hear about cpyext and PyQt! Do desktop ui's apps gain alot of performance from being on pypy? Would kivy go faster seeing as it has a large chunk of widgets implemented in python?
All core features in Kivy are implemented in Cython. PyPy is slower with Cython.
isn't the cpyext going to be the answer for pyQt and cython? Or are you saying pyQt should perform greater?
The python interpreter size is 3.5MB where as pypy intepreter size is almost 40MB. As it has huge size difference it is impossible to replace in embedded projects
Is there any way to reduce it or any suggestions to implement in embedded area.Why is this difference.
Vectorization extended. PowerPC and s390x
s390x backend have been enhanced. Both can now vectorize loops via SIMD
instructions. Special thanks to IBM for funding this work.
If you are not familiar with this topic you can read more details here.
There are many more enhancements under the hood. Most notably, all pure operations are now delayed until the latest possible point. In some cases indices have been calculated more than once or they needed an additional register, because the old value is still used. Additionally it is now possible to load quadword-aligned memory in both PPC and s390x (x86 currently cannot do that).
NumPy & CPyExt
The community and core developers have been moving CPyExt towards a complete, but emulated, layer for CPython C extensions. This is great, because the one restriction preventing the wider deployment of PyPy in several scenarios will hopefully be removed. However, we advocate not to use CPyExt, but rather to not write C code at all (let PyPy speed up your Python code) or use cffi.The work done here to support vectorization helps micronumpy (NumPyPy) to speed up operations for PPC and s390x. So why is PyPy supporting both NumPyPy and NumPy, do we actually need both? Yes, there are places where gcc can beat the JIT, and places where the tight integration between NumPyPy and PyPy is more performant. We do have plans to integrate both, hijacking the C-extension method calls to use NumPyPy where we know NumPyPy can be faster.
Just to give you an idea why this is a benefit:
NumPy arrays can carry custom dtypes and apply user defined python functions on the arrays. How could one optimize this kind of scenario? In a traditional setup, you cannot. But as soon as NumPyPy is turned on, you can suddenly JIT compile this code and vectorize it.
Another example is element access that occurs frequently, or any other calls that cross between Python and the C level frequently.
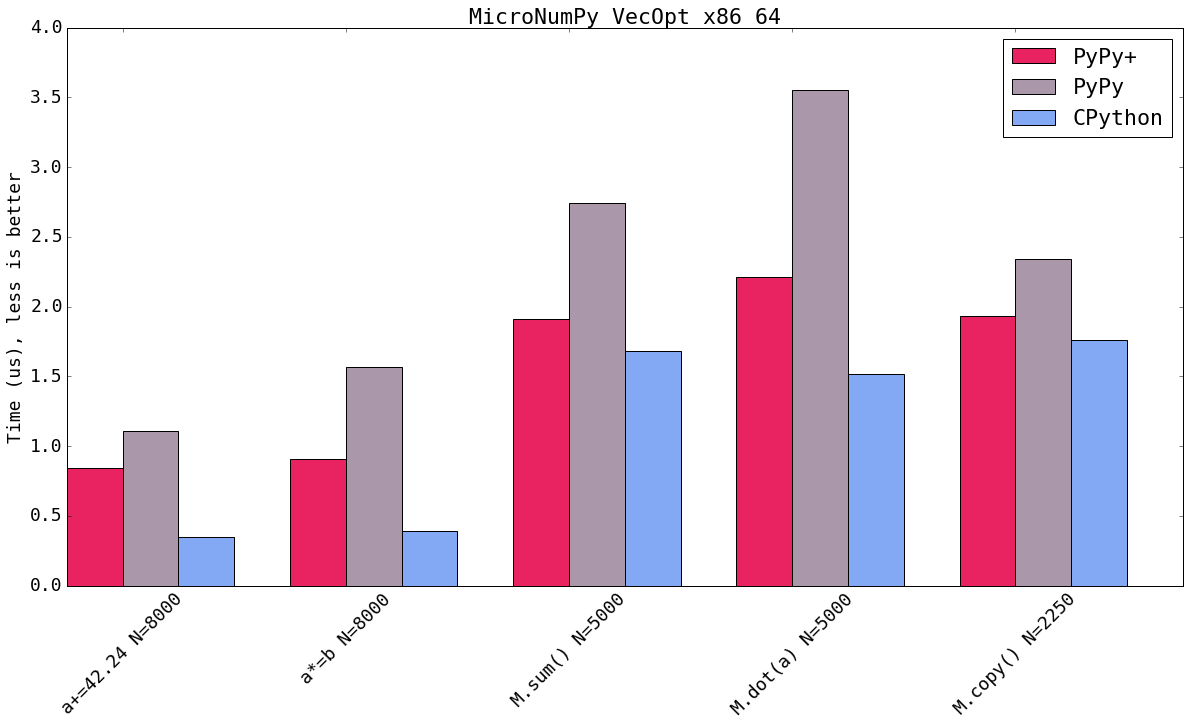
Benchmarks
Let's have a look at some benchmarks reusing mikefc's numpy benchmark suite (find the forked version here). I only ran a subset of microbenchmarks, showing that the core functionality isfunctioning properly. Additionally it has been rewritten to use perf instead of the timeit stdlib module.
Setup
x86 runs on a Intel i7-2600 clocked at 3.40GHz using 4 cores. PowerPC runs on the Power 8 clocked at 3.425GHz providing 160 cores. Last but not least the mainframe machine clocked up to 4 GHz, but fully virtualized (as it is common for such machines). Note that PowerPC is a non private remote machine. It is used by many users and it is crowded with processes. It is hard to extract a stable benchmark there.x86 ran on Fedora 24 (kernel version of 4.8.4), PPC ran on Fedora 21 (kernel version 3.17.4) and s390x ran on Redhat Linux 7.2 (kernel version 3.10.0). Respectivley, numpy on cpython had openblas available on x86, no blas implementation were present on s390x and PPC provided blas and lapack.
As you can see all machines run very different configurations. It does not make sense to compare across platforms, but rather implementations on the same platform.
{kind=link}

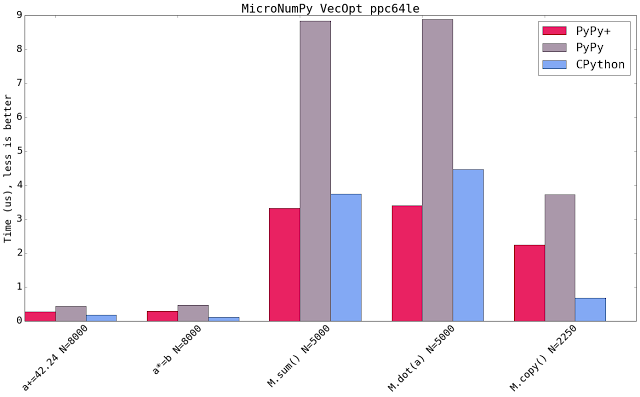
Blue shows CPython 2.7.10+ available on that platform using the latest NumPy (1.11). Micro NumPy is used for PyPy. PyPy+ indicates that the vectorization optimization is turned on.
All bar charts show the median value of all runs (5 samples, 100 loops, 10 inner loops, for the operations on vectors (not matrices) the loops are set to 1000). PyPy additionally gets 3 extra executions to warmup the JIT.
The comparison is really comparing speed of machine code. It compares the PyPy's JIT output vs GCC's output. It has little to do with the speed of the interpreter.
Both new SIMD backends speedup the numeric kernels. Some times it is near to the speed of CPython, some times it is faster. The maximum parallelism very much depends on the extension emitted by the compiler. All three SIMD backends have the same vector register size (which is 128 bit). This means that all three behave similar but ppc and s390x gain more because they can load 128bit of memory from quadword aligned memory.
Future directions
Python is achieving rapid adoption in data science. This is currently a trend emerging in Europe, and Python is already heavily used for data science in the USA many other places around the world.PyPy can make a valuable contribution for data scientists, helping them to rapidly write scientific programs in Python and run them at near native speed. If you happen to be in that situation, we are eager to hear you feedback or resolve your issues and also work together to improve the performance of your,
code. Just get in touch!
Richard Plangger (plan_rich) and the PyPy team
As you are talking about GCC beating your JIT, you are using your own vectorizing compiler right?
I wonder if this is a feasible approach. Can you really compete with the years if not decades of work that went into the vectorizers of GCC and LLVM?
Wouldn't it make more sense to plug into GCC's and LLVM's JIT API's (yes GCC has a JIT) for this type of code?
What does PyPy bring to the table that the existing JIT's do not for numerical code?
It's good to see pypy making progress on using python as a toolkit for data science. In addition to numpy, pandas/scipy also needs to work well for me to switch.
Also, a lot of data science is currently being run on windows and the x64 port of pypy hasn't had much traction in the last several years. If these 2 issues are solved (pandas/scipy being supported on a x64 windows pypy) then there should be no reason to keep using CPython.
I think most of pypy dev/users use Linux/MacOsx only, so there is no strong motivation to support win64 at the moment.
PyPy3 5.5.0 released
We're pleased to announce the release of PyPy3 v5.5.0. Coming four months after PyPy3.3 v5.2, it improves compatibility with Python 3.3 (3.3.5). We strongly recommend updating from previous PyPy3 versions.
We would like to thank all of the people who donated to the py3k proposal for supporting the work that went into this release.
You can download the PyPy3.3 v5.5.0 release here: https://pypy.org/download.html
- Improved Python 3.3.5 support.
- os.get_terminal_size(), time.monotonic(), str.casefold()
- faulthandler module
- There are still some missing features such as a PEP 393-like space efficient string representation and including performance regressions (e.g. issue #2305). The focus for this release has been updating to 3.3 compatibility. Windows is also not yet supported.
- ensurepip is also included (it's only included in CPython 3 >= 3.4).
- Buffer interface improvements (numpy on top of cpyext)
- Several JIT improvements (force-virtual-state, residual calls)
- Search path for libpypy-c.so has changed (helps with cffi embedding on linux distributions)
- Improve the error message when the user forgot the "self" argument of a method
- Many more small improvements, please head over to our documentation for more information
Towards Python 3.5
What is PyPy?
PyPy is a very compliant Python interpreter, almost a drop-in replacement for CPython 2.7.10 and 3.3.5. It's fast due to its integrated tracing JIT compiler.We also welcome developers of other dynamic languages to see what RPython can do for them.
This release supports:
- x86 machines on most common operating systems except Windows
- newer ARM hardware (ARMv6 or ARMv7, with VFPv3) running Linux
- big- and little-endian variants of PPC64 running Linux
- s390x running Linux
you are using PyPy, please tell us about it!
Cheers
The PyPy Team
Wow! 3.5? That would be incredible. Shouldn't there be more hype around JITted asyncio applications?
Butla: I do totally agree, pypy not only for numeric code anymore but also for parallel production servers.
The performance difference between 5.5 and 5.2 is awesome! For my heavy string and lists-of-strings processing tool, 5.5 needs about 25% less time for the same task. Thank you so much!
RevDB released, v5.4.1
Hi all,
The first beta version of RevDB is out! Remember that RevDB is a reverse debugger for Python. The idea is that it is a debugger that can run forward and backward in time, letting you more easily understand your subtle bug in your big Python program.
RevDB should work on almost any Python program. Even if you are normally only using CPython, trying to reproduce the bug with RevDB is similar to trying to run the program on a regular PyPy---usually it just works, even if not quite always.
News from the alpha version in the previous blog post include notably support for:
- Threads.
- CPyExt, the compatibility layer of PyPy that can run CPython C extension modules.
You need to build it yourself for now. It is tested on 64-bit Linux. 32-bit Linux, OS/X, and other POSIX platforms should all either work out of the box or be just a few fixes away (contributions welcome). Win32 support is a lot more involved but not impossible.
See https://bitbucket.org/pypy/revdb/ for more information!
Armin
PyPy 5.4.1 bugfix released
- Update list of contributors in documentation and LICENSE file, this was unfortunately left out of 5.4.0. My apologies to the new contributors
- Allow tests run with
-Ato findlibm.soeven if it is a script not a dynamically loadable file - Bump
sys.setrecursionlimit()when translating PyPy, for translating with CPython - Tweak a float comparison with 0 in
backendopt.inlineto avoid rounding errors - Fix for an issue for translating the sandbox
- Fix for and issue where
unicode.decode('utf8', 'custom_replace')messed up the last byte of a unicode string sometimes - Update built-in cffi to version 1.8.1
- Explicitly detect that we found as-yet-unsupported OpenSSL 1.1, and crash translation with a message asking for help porting it
- Fix a regression where a PyBytesObject was forced (converted to a RPython object) when not required, reported as issue #2395
What is PyPy?
We also welcome developers of other dynamic languages to see what RPython can do for them.
This release supports:
- x86 machines on most common operating systems (Linux 32/64, Mac OS X 64, Windows 32, OpenBSD, FreeBSD),
- newer ARM hardware (ARMv6 or ARMv7, with VFPv3) running Linux,
- big- and little-endian variants of PPC64 running Linux,
- s390x running Linux
Cheers
The PyPy Team
PyPy2 v5.4 released - incremental improvements and enhancements
We updated built-in cffi support to version 1.8, which now supports the “limited API” mode for c-extensions on CPython >=3.2.
We improved tooling for the PyPy JIT, and expanded VMProf support to OpenBSD and Dragon Fly BSD
As always, this release fixed many issues and bugs raised by the growing community of PyPy users. We strongly recommend updating.
You can download the PyPy2 v5.4 release here:
We would like to thank our donors for their continued support of the PyPy project. We would also like to thank our contributors and encourage new people to join the project. PyPy has many layers and we need help with all of them: PyPy and RPython documentation improvements, testing and adapting popular modules to run on PyPy, or general help with making RPython’s JIT even better.
What is PyPy?
PyPy is a very compliant Python interpreter, almost a drop-in replacement for CPython 2.7. It’s fast (PyPy and CPython 2.7 performance comparison) due to its integrated tracing JIT compiler.We also welcome developers of other dynamic languages to see what RPython can do for them.
This release supports:
- x86 machines on most common operating systems (Linux 32/64, Mac OS X 64, Windows 32, OpenBSD, FreeBSD)
- newer ARM hardware (ARMv6 or ARMv7, with VFPv3) running Linux
- big- and little-endian variants of PPC64 running Linux
- s390x running Linux
What is New?
(since the release of PyPy 5.3 in June, 2016)
There are many incremental improvements to RPython and PyPy, the complete listing is here. Mozilla generously sponsored work toward python 3.5 compatibility, and we are beginning to see some cross-over improvements of RPython and PyPy2.7 as a result.Please update, and continue to help us make PyPy better. Cheers
The PyPy Team
Is this available on the PPA ?
(if it is, which one, possibly I have the wrong one) - at the moment I have
Get:2 https://ppa.launchpad.net/pypy/ppa/ubuntu xenial/main amd64 pypy amd64 5.3.1+dfsg-1~ppa1~ubuntu16.04 [7,754 kB]
?
PyPy Tooling Upgrade: JitViewer and VMProf
We are happy to announce a major JitViewer (JV) update.
JV allows you to inspect RPython's internal compiler representation (the language in which PyPy is implemented) including the generated machine code of your program. It can graphically show you details of the JIT compiled code and helps you pinpoint issues in your program.
VMProf is a statistical CPU profiler for python imposing very little overhead at runtime.
Both VMProf and JitViewer share a common goal: Present useful information for your python program.
The combination of both can reveal more information than either alone.
That is the reason why they are now both packaged together.
We also updated vmprof.com with various bug fixes and changes including an all new interface to JV.
This work was done with the goal of improving tooling and libraries around the Python/PyPy/RPython ecosystem.
Some of the tools we have developed:
- CFFI - Foreign Function Interface that avoids CPyExt (CFFI docs)
- RevDB - A reverse debugger for python (RevDB blog post)
and of course the tools we discuss here:
- VMProf - A statistical CPU profiler (VMProf docs)
- JitViewer - Visualization of the log file produced by RPython (JitLog docs)
A "brand new" JitViewer
JitViewer has two pieces: you create a log file when running your program, and then use a graphic tool to view what happened.
The old logging format was a hard-to-maintain, plain-text-logging facility. Frequent changes often broke internal tools.
Additionally, the logging output of a long running program required a lot of disk space.
Our new binary format encodes data densely, makes use of some compression (gzip), and tries to remove repetition where possible.
It also supports versioning for future proofing and can be extended easily.
And *drumroll* you no longer need to install a tool to view the log yourself
anymore! The whole system moved to vmprof.com and you can use it any time.
Sounds great. But what can you do with it? Here are two examples for a PyPy user:
PyPy crashed? Did you discover a bug?
For some hard to find bugs it is often necessary to look at the compiled code. The old
procedure often required you to upload a plain text file which was hard to parse and to look through.
A better way to share a crash report is to install the ``vmprof`` module from PyPi and execute either of the two commands:
# this program does not crash, but has some weird behaviour
$ pypy -m jitlog --web <your program args>
...
PyPy Jitlog: https://vmprof.com/#/<hash>/traces
# this program segfaults
$ pypy -m jitlog -o /tmp/log <your program args>
...
<Segfault>
$ pypy -m jitlog --upload /tmp/log
PyPy Jitlog: https://vmprof.com/#/<hash>/traces
Providing the link in the bug report allows PyPy developers to browse and identify potential issues.
Speed issues
VMProf is a great tool to find hot spots that consume a lot of time in your program. As soon as you have identified code that runs slowly, you can switch to jitlog and maybe pinpoint certain aspects that do not behave as expected. You will find an overview, and are able to browse the generated code. If you cannot make sense of all that, you can just share the link with us and we can have a look too.
Future direction
We hope that the new release will help both PyPy developers and PyPy users resolve potential issues and easily point them out.
Here are a few ideas what might come in the next few releases:
- Combination of CPU profiles and the JITLOG (sadly did not make it into the current release).
- Extend vmprof.com to be able to query vmprof/jitlog.
An example query for vmprof: 'methods.callsites() > 5' and
for the jitlog would be 'traces.contains('call_assembler').hasbridge('*my_func_name*')'. - Extend the jitlog to capture the information of the optimization stage.
Richard Plangger (plan_rich) and the PyPy team
https://www.vmprof.com/ doesn't work, but https://vmprof.com/ does. Please fix your DNS.
PyPy gets funding from Mozilla for Python 3.5 support
"Python 2.x versus Python 3.x": this is by now an old question. In the eyes of some people Python 2 is here to stay, and in the eyes of others Python has long been 3 only.
PyPy's own position is that PyPy will support Python 2.7 forever---the RPython language in which PyPy is written is a subset of 2.7, and we have no plan to upgrade that. But at the same time, we want to support 3.x. This is particularly true now: a relatively recent development is that Python 3.5 seems to attract more and more people. The "switch" to Python 3.x might be starting to happen.
Correspondingly, PyPy has been searching for a while for a way to support a larger-scale development effort. The goal is to support not just any old version of Python 3.x, but Python 3.5, as this seems to be the version that people are switching to. PyPy is close to supporting all of Python 3.3 now; but the list of what is new in Python 3.4 and 3.5 is far, far longer than anyone imagines. The long-term goal is also to get a version of "PyPy3" that is as good as "PyPy2" is, including its performance and its cpyext layer (CPython C API interoperability), for example.
So, the end result: Mozilla recently decided to award $200,000 to Baroque Software to work on PyPy as part of its Mozilla Open Source Support (MOSS) initiative. This money will be used to implement the Python 3.5 features in PyPy. Within the next year, we plan to use the money to pay four core PyPy developers half-time to work on the missing features and on some of the big performance and cpyext issues. This should speed up the progress of catching up with Python 3.x significantly. We are extremely thankful to Mozilla for supporting us in this way, and will keep you updated on the progress via this blog.
Great to hear of this development. I'm one of those "Python has long been 3 only" developers, but have had an eye on PyPy for a long time and even donated several times. Planning to switch to PyPy when 3.5 support lands.
glad to hear that.
To me, the time to switch to py3 depends upon the maturity of pypy 3.
I have used pypy 2 for a while in production, so far so good.
Great news!
I'm one of those "Python 3 only". The switch was terrible for the community, but Python 3 is superior than 2 in my opinion.
RPython 3 would be great to, but it's propably complete inviable.
Fantastic news! Thanks for your work, and thanks Mozilla for their support :)
Is there any chance optional typing information will be used to help the JIT?
200,000 sounds like a lot of money but it is two developers for a year at less than Silicon Valley wages.
This is huge news! Corporate sponsorship of open source projects is a beautiful thing for us all. Congrats to the PyPy team. You really deserve this kind of support for all of your hard work and perseverance over the years.
Given that Python 3.6 will be going beta next month, perhaps that should be your target instead of 3.5 but you know your craft better than I do.
Those of you who would be interested to pay Mozilla back for this investment might want to help port the following 9 Mozilla projects to Python 3:
* mozrunner, moznetwork, mozdevice, mozprocess, mozprofile, mozfile, mozinfo, mozlog, mozcrash
These nine Python 2 projects are all in the Top 150 PyPI downloads of all time and each of them has been downloaded with pip more than 5 million times. Currently 92% of the Top 200 PyPI packages are Python3 compatible. Converting these 9 Mozbase modules to Python 3 would bump that number up to 96.5%. It would also probably push us over the line where 50% of the Top 4,000 PyPI packages are Python 3 compatible. This kind of momentum would be welcome news as the Python community continues our move to Python 3.
Why Python 3.5 instead of 3.6? That's because 3.5 is the version that attracts people. Python 3.6 will only be out of beta in december and my own wild guess is that it won't immediately attract all the 2.7 people, who grew accustomed to sticking to a known unchanging version. So the deal with Mozilla is to get a PyPy 3.5 working as well as possible; it is better than getting a PyPy 3.6 that (like current versions of PyPy 3) has downsides in completeness and performance.
Great news! I Can't wait to the moment we get an stable Python3 PyPy! Congratulations!
Great news! I Can't wait to the moment we get an stable Python3 PyPy! Congratulations!
TL;DR. Python 3.5 is a "good enough" and seems a future-proof language.
I was in charge of deciding which version of Python to use at my job. We started the development of a framework supporting Python 2.7 and Python >=3.4, but we recently switched to a Python 3 only development. The whole python 2 vs 3 thing was quite confusing to the operations department and developers that are not proficient with Python.
There was a quite thorough assessment of the features, and we decided to stick to Python 3.5, at least for the next decade or so. On the Python 3 side, one of the reasons was that the async/await syntax allows junior developers to understand (more or less) asynchronous programming, while coroutines+decorators are quite a mess. We still have some Red Hat instances that use Python 3.4, but as soon as we get rid of them, everything will be Python 3.5.
This is amazing news! I use Python3 extensively in private research projects. Unfortunately, I have been in the position of choosing between Python3 and having a high-performance interpreter implementation. Testing the PyPy 3.3.5 alpha shows all-around disappointing performance in our string-manipulation-heavy projects making intense use of unicode, so I can only recommend our team to stay with CPython for both performance and compatibility.
I am very excited to hear that PyPy3 will be getting more of the specific attention it deserves, with Python 3.5 support to boot!
Good news, and you definitely deserve it. But I guess this will take virtually all of the PyPy team's resources for the next one-two years, what does this means for other in-progress innovations, in particular STM-GC? I donated but it looks like the money is not being spent.
If continuing the improvements to CPython support means PyPy will become an option for more programs, that would be great. The (few) red lines in https://packages.pypy.org/ and lower performance for others are still blockers for many users.
@PvdE: I'll admit that the STM-GC is not actively going anywhere right now. STM is hard, unsurprizingly. There is still a bit being done by Remi (working at an academic institution where he doesn't need the money). For me, I am part of the Python 3.5 team, but I might also come back to STM-GC soon. We expect not all our resources to be consumed by Python 3.5. In fact, the money covers four half-time jobs (and flexibility allows someone to do less than half-time while someone else does more).
This is great news.
A developer's decision to target Python 3 over Python 2 in their projects is more fundamental than deciding which interpreter to use. People use Python 3 because it's future-proof, to take advantage of its new features and to do their bit in driving the Python ecosystem forward. For me and I imagine many others, being curious about PyPy hasn't been enough to override all those factors.
I think there's a huge untapped audience out there waiting for first-class support for modern Python in PyPy before giving it a shot. I hope to see a big bump in PyPy adoption with this move, and a corresponding bump in funding and support for PyPy's development.
Thanks for your fantastic work!
Great news! Will this include making numpy work with Python3 pypy? That's the main thing preventing me from evaluating pypy for my Python3-only OpenGL application.
@JP cpyext compatibility is one of the milestones, and we currently pass over 99% of the upstream NumPy test suite using PyPy 2.7, so it all should Just Work
Getting PyPy3 to 3.5 status is a good start considering that the current LTS version of Ubuntu (16.04) has 3.5 and that is going to be supported for a while.
Great news! Pypy's lack of Python 3 support is the biggest reason I haven't switched yet. It technically supports most of 3.3 already, but since Pypy3 is slower than CPython, it may as well not exist. Hopefully you'll also work out the performance issues in Pypy 3 as well.
This is fantastic! How close to ready is the async/await syntax? Any chance it could be snuck in the 3.5 release?
As far as I know, curio (and maybe asyncio) wouldn't run if we didn't properly support async/await already.
Great news, you are doing awesome work! Any chance cpyext will be included in the alpha?
cpyext will be included. We expect C-API support to be approximately on par with pypy2, e.g. the pypy3 nightlies have nearly complete support for numpy.
Awesome work!
@Benjamin, async def / async for / async with / await were all introduced in Python 3.5.
This is wonderful work, congrats!
This is great. It would be good to include some alternate asyncio back-ends as well if they work with pypy.
For instance, my current project uses libuv and gbulb in different components.
Will this work with uvloop? I'm curious as I would like to get Sanic running on this! :-)
From what I've read on #pypy (sorry if I'm messing something up): uvloop is a drop-in replacement of asyncio, but asyncio is faster on PyPy. PyPy's JIT for pure Python code beats the overheads of the CPython API compatibility layer (in this case, via Cython). Moreover, considering the whole application, using asyncio on PyPy easily beats using uvloop on CPython. So, as long as it remains a fully compatible replacement, you can "drop it out" and use asyncio instead on PyPy.