An Efficient and Elegant Regular Expression Matcher in Python
Two weeks ago, I was at the Workshop Programmiersprachen und Rechenkonzepte, a yearly meeting of German programming language researchers. At the workshop, Frank Huch and Sebastian Fischer gave a really excellent talk about an elegant regular expression matcher written in Haskell. One design goal of the matcher was to run in time linear to the length of the input string (i.e. without backtracking) and linear in the size of the regular expression. The memory use should also only be linear in the regular expression.
During the workshop, some of the Haskell people and me then implemented the algorithm in (R)Python. Involved were Frank, Sebastian, Baltasar Trancón y Widemann, Bernd Braßel and Fabian Reck.
In this blog post I want to describe this implementation and show the code of it, because it is quite simple. In a later post I will show what optimizations PyPy can perform on this matcher and also do some benchmarks.
A Note on terminology: In the rest of the post "regular expression" is meant in the Computer Science sense, not in the POSIX sense. Most importantly, that means that back-references are not allowed.
Another note: This algorithm could not be used to implement PyPy's re module! So it won't help to speed up this currently rather slow implementation.
Implementing Regular Expression Matchers¶
There are two typical approaches to implement regular expression. A naive one is to use a back-tracking implementation, which can lead to exponential matching times given a sufficiently evil regular expression.
The other, more complex one, is to transform the regular expression into a non-deterministic finite automaton (NFA) and then transform the NFA into a deterministic finite automaton (DFA). A DFA can be used to efficiently match a string, the problem of this approach is that turning an NFA into a DFA can lead to exponentially large automatons.
Given this problem of potential memory explosion, a more sophisticated approach to matching is to not construct the DFA fully, but instead use the NFA for matching. This requires some care, because it is necessary to keep track of which set of states the automaton is in (it is not just one state, because the automaton is non-deterministic).
The algorithm described here is essentially equivalent to this approach, however it does not need an intermediate NFA and represents a state of a corresponding DFA as marked regular expression (represented as a tree of nodes). For many details about an alternative approach to implement regular expressions efficiently, see Russ Cox excellent article collection.
The Algorithm¶
In the algorithm the regular expression is represented as a tree of nodes. The leaves of the nodes can match exactly one character (or the epsilon node, which matches the empty string). The inner nodes of the tree combine other nodes in various ways, like alternative, sequence or repetition. Every node in the tree can potentially have a mark. The meaning of the mark is that a node is marked, if that sub-expression matches the string seen so far.
The basic approach of the algorithm is that for every character of the input string the regular expression tree is walked and a number of the nodes in the regular expression are marked. At the end of the string, if the top-level node is marked, the string matches, otherwise it does not. At the beginning of the string, one mark gets shifted into the regular expression from the top, and then the marks that are in the regex already are shifted around for every additional character.
Let's start looking at some code, and an example to make this clearer. The base class of all regular expression nodes is this:
class Regex(object):
def __init__(self, empty):
# empty denotes whether the regular expression
# can match the empty string
self.empty = empty
# mark that is shifted through the regex
self.marked = False
def reset(self):
""" reset all marks in the regular expression """
self.marked = False
def shift(self, c, mark):
""" shift the mark from left to right, matching character c."""
# _shift is implemented in the concrete classes
marked = self._shift(c, mark)
self.marked = marked
return marked
The match function which checks whether a string matches a regex is:
def match(re, s):
if not s:
return re.empty
# shift a mark in from the left
result = re.shift(s[0], True)
for c in s[1:]:
# shift the internal marks around
result = re.shift(c, False)
re.reset()
return result
The most important subclass of Regex is Char, which matches one concrete character:
class Char(Regex):
def __init__(self, c):
Regex.__init__(self, False)
self.c = c
def _shift(self, c, mark):
return mark and c == self.c
Shifting the mark through Char is easy: a Char instance retains a mark that is shifted in when the current character is the same as that in the instance.
Another easy case is that of the empty regular expression Epsilon:
class Epsilon(Regex):
def __init__(self):
Regex.__init__(self, empty=True)
def _shift(self, c, mark):
return False
Epsilons never get a mark, but they can match the empty string.
Alternative¶
Now the more interesting cases remain. First we define an abstract base class Binary for the case of composite regular expressions with two children, and then the first subclass Alternative which matches if either of two regular expressions matches the string (usual regular expressions syntax a|b).
class Binary(Regex):
def __init__(self, left, right, empty):
Regex.__init__(self, empty)
self.left = left
self.right = right
def reset(self):
self.left.reset()
self.right.reset()
Regex.reset(self)
class Alternative(Binary):
def __init__(self, left, right):
empty = left.empty or right.empty
Binary.__init__(self, left, right, empty)
def _shift(self, c, mark):
marked_left = self.left.shift(c, mark)
marked_right = self.right.shift(c, mark)
return marked_left or marked_right
An Alternative can match the empty string, if either of its children can. Similarly, shifting a mark into an Alternative shifts it into both its children. If either of the children are marked afterwards, the Alternative is marked too.
As an example, consider the regular expression a|b|c, which would be represented by the objects Alternative(Alternative(Char('a'), Char('b')), Char('c')). Matching the string "a" would lead to the following marks in the regular expression objects (green nodes are marked, white ones are unmarked):
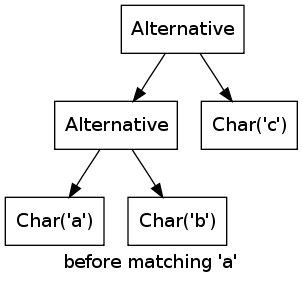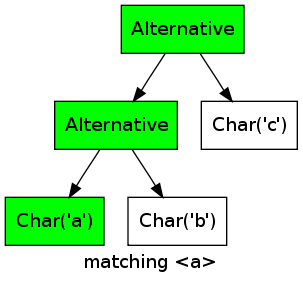
At the start of the process, no node is marked. Then the first char is matched, which adds a mark to the Char('a') node, and the mark will propagate up the two Alternative nodes.
Repetition¶
The two remaining classes are slightly trickier. Repetition is used to match a regular expression any number of times (usual regular expressions syntax a*):
class Repetition(Regex):
def __init__(self, re):
Regex.__init__(self, True)
self.re = re
def _shift(self, c, mark):
return self.re.shift(c, mark or self.marked)
def reset(self):
self.re.reset()
Regex.reset(self)
A Repetition can always match the empty string. The mark is shifted into the child, but if the Repetition is already marked, this will be shifted into the child as well, because the Repetition could match a second time.
As an example, consider the regular expression (a|b|c)* matching the string abcbac:
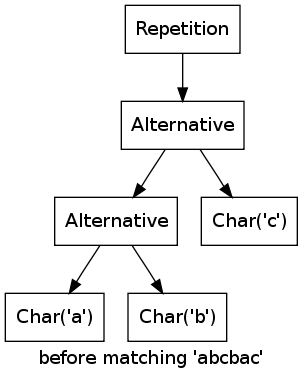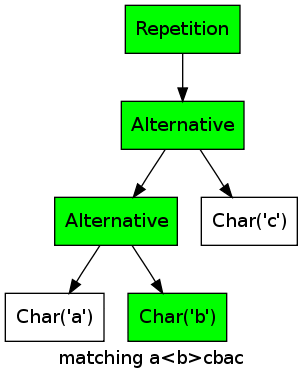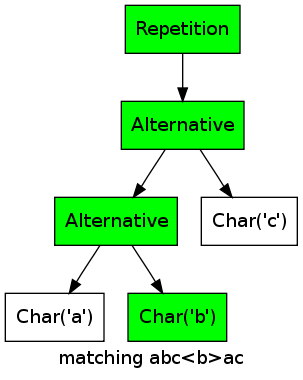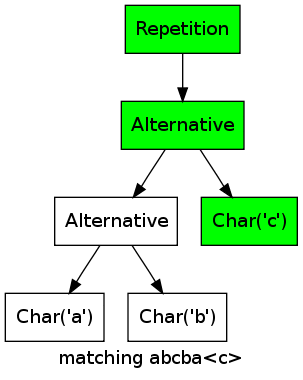
For every character, one of the alternatives matches, thus the repetition matches as well.
Sequence¶
The only missing class is that for sequences of expressions, Sequence (usual regular expressions syntax ab):
class Sequence(Binary):
def __init__(self, left, right):
empty = left.empty and right.empty
Binary.__init__(self, left, right, empty)
def _shift(self, c, mark):
old_marked_left = self.left.marked
marked_left = self.left.shift(c, mark)
marked_right = self.right.shift(
c, old_marked_left or (mark and self.left.empty))
return (marked_left and self.right.empty) or marked_right
A Sequence can be empty only if both its children are empty. The mark handling is a bit delicate. If a mark is shifted in, it will be shifted to the left child regular expression. If that left child is already marked before the shift, that mark is shifted to the right child. If the left child can match the empty string, the right child gets the mark shifted in as well.
The whole sequence matches (i.e. is marked), if the left child is marked after the shift and if the right child can match the empty string, or if the right child is marked.
Consider the regular expression abc matching the string abcd. For the first three characters, the marks wander from left to right, when the d is reached, the matching fails.
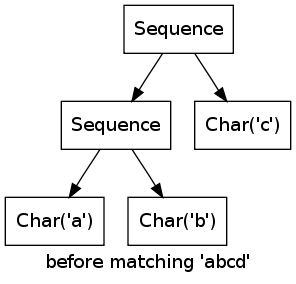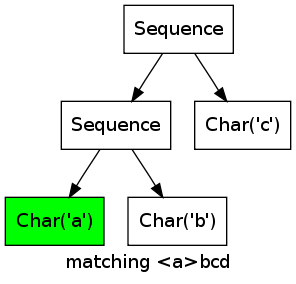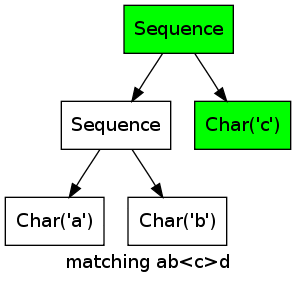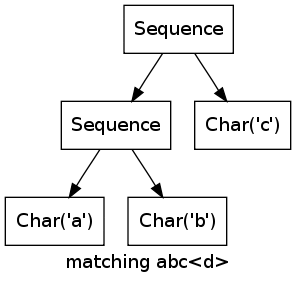
More Complex Example¶
As a more complex example, consider the expression ((abc)*|(abcd))(d|e) matching the string abcabcabcd.
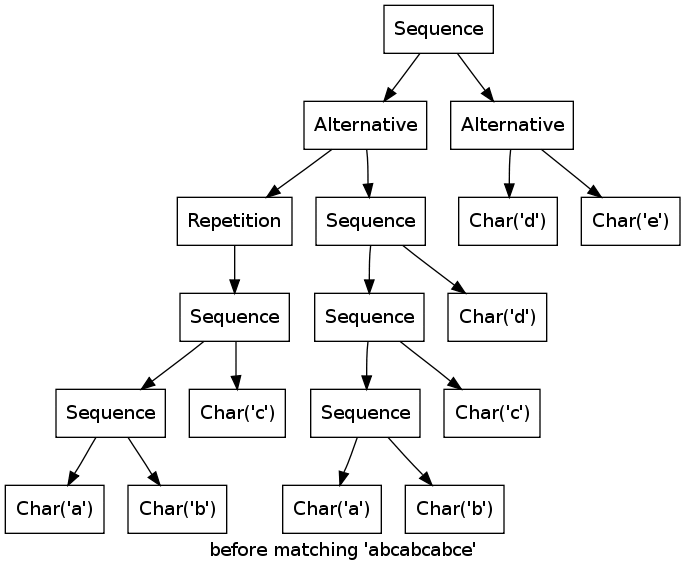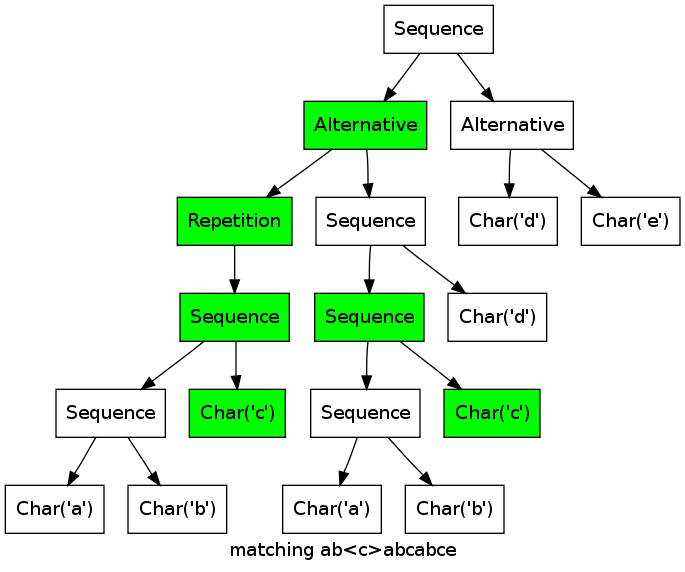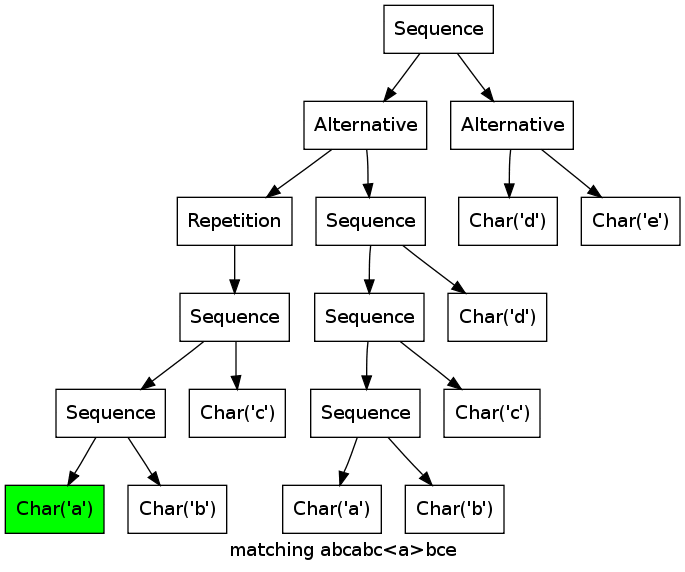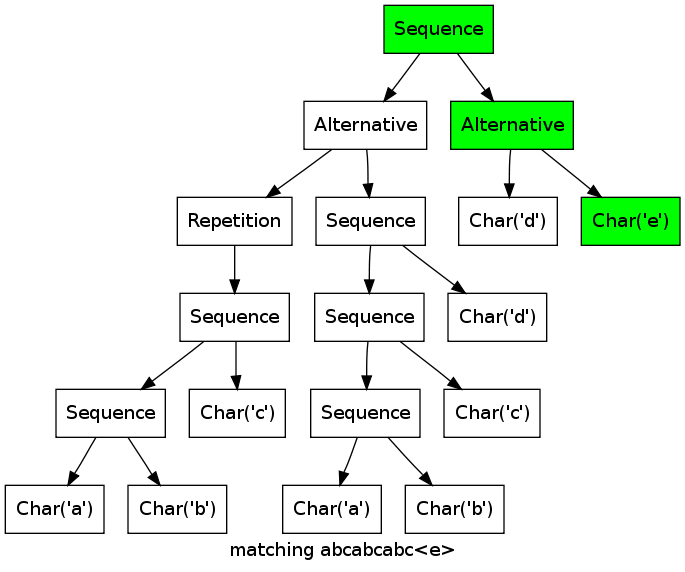
Note how the two branches of the first alternative match the first abc in parallel, until it becomes clear that only the left alternative (abc)* can work.
Complexity¶
The match function above loops over the entire string without going back and forth. Each iteration goes over the whole tree every time. Thus the complexity of the algorithm is O(m*n) where m is the size of the regular expression and n is the length of the string.
Summary & Outlook¶
So, what have we achieved now? The code shown here can match regular expressions with the desired complexity. It is also not much code. By itself, the Python code shown above is not terribly efficient. In the next post I will show how the JIT generator can be used to make the simple matcher shown above really fast.
Comments
Have you seen Russ Cox's series of articles about regular expressions?
Google Chrome's regexp library is also interesting.
Google appears to have put a lot of research in efficient regexp algorithms while paying attention to backwards-compatibility concerns, as existing applications often rely on backtracking.
Limited backreferences can be integrated within this pattern matching scheme. General backreferences are only possible with backtracking but unless you want to solve NP complete problems using POSIX style regexps they might not be necessary.
Marius: The Russ Cox site is linked from the article :-).
Kay: Thanks for the link, will check it out.
I do not use regular expressions very heavily and am very new to pypy in general (1.2 works pretty good for me on my pure python code). From this article I don't see a full explaination why this basic algorithm couldn't be used for pypy. Is it primarily due to concerns about backward compatiblity or something more interesting? I am looking forward to the article to come about applying the JIT.
@Thomas Python's re library requires backtracking.
This is just beautiful, I hope some version of this will be available for PyPy users: sandboxing + non-pathological REs sounds like a nice combo.
Though these regexes can't be used as a drop-in replacement for the re module, if there were strikingly faster it might be worth having them as an alternative. The backtracking features are so seldom required that a faster, non-backtracking algorithm might prove popular with people who worry about matching speed.
It would be fun to read an article where you take the real Python regexes and apply PyPy's JIT code generation to them, i.e. when you call re.compile(...), you'd get native code out of it, specialized for the regex being compiled. After all, haven't you used the JIT on "toy" languages before? Regexes are a "toy" language, albeit a useful one..
Anonymous2: Yes, but PyPy's current implementation of the re module is a bit of a mess, and not really fast. It's rather unclear how easy/possible it would be to generate a good JIT for it.
Instead of a "special" interpreter for REs in RPython, and a JIT for it, what about "compiling" REs to Python bytecode, and letting the existing PyPy JIT trace and compile them if they end up being used often enough? This is probably slower in the case of lots of throwaway REs that are used once, but when a few REs are used repeatedly it ought to work.
"As an example, consider the regular expression a|b|c, which would be represented by the objects Alternative(Alternative(Char('a'), Char('b')), Char('c'))"
But how to create such a representation, when you scan input regex literal by literal?