PyPy for low-latency systems
PyPy for low-latency systems¶
Recently I have merged the gc-disable branch, introducing a couple of features which are useful when you need to respond to certain events with the lowest possible latency. This work has been kindly sponsored by Gambit Research (which, by the way, is a very cool and geeky place where to work, in case you are interested). Note also that this is a very specialized use case, so these features might not be useful for the average PyPy user, unless you have the same problems as described here.The PyPy VM manages memory using a generational, moving Garbage Collector. Periodically, the GC scans the whole heap to find unreachable objects and frees the corresponding memory. Although at a first look this strategy might sound expensive, in practice the total cost of memory management is far less than e.g. on CPython, which is based on reference counting. While maybe counter-intuitive, the main advantage of a non-refcount strategy is that allocation is very fast (especially compared to malloc-based allocators), and deallocation of objects which die young is basically for free. More information about the PyPy GC is available here.
As we said, the total cost of memory managment is less on PyPy than on CPython, and it's one of the reasons why PyPy is so fast. However, one big disadvantage is that while on CPython the cost of memory management is spread all over the execution of the program, on PyPy it is concentrated into GC runs, causing observable pauses which interrupt the execution of the user program.
To avoid excessively long pauses, the PyPy GC has been using an incremental strategy since 2013. The GC runs as a series of "steps", letting the user program to progress between each step.
The following chart shows the behavior of a real-world, long-running process:

The orange line shows the total memory used by the program, which increases linearly while the program progresses. Every ~5 minutes, the GC kicks in and the memory usage drops from ~5.2GB to ~2.8GB (this ratio is controlled by the PYPY_GC_MAJOR_COLLECT env variable).
The purple line shows aggregated data about the GC timing: the whole collection takes ~1400 individual steps over the course of ~1 minute: each point represent the maximum time a single step took during the past 10 seconds. Most steps take ~10-20 ms, although we see a horrible peak of ~100 ms towards the end. We have not investigated yet what it is caused by, but we suspect it is related to the deallocation of raw objects.
These multi-millesecond pauses are a problem for systems where it is important to respond to certain events with a latency which is both low and consistent. If the GC kicks in at the wrong time, it might causes unacceptable pauses during the collection cycle.
Let's look again at our real-world example. This is a system which continuously monitors an external stream; when a certain event occurs, we want to take an action. The following chart shows the maximum time it takes to complete one of such actions, aggregated every minute:
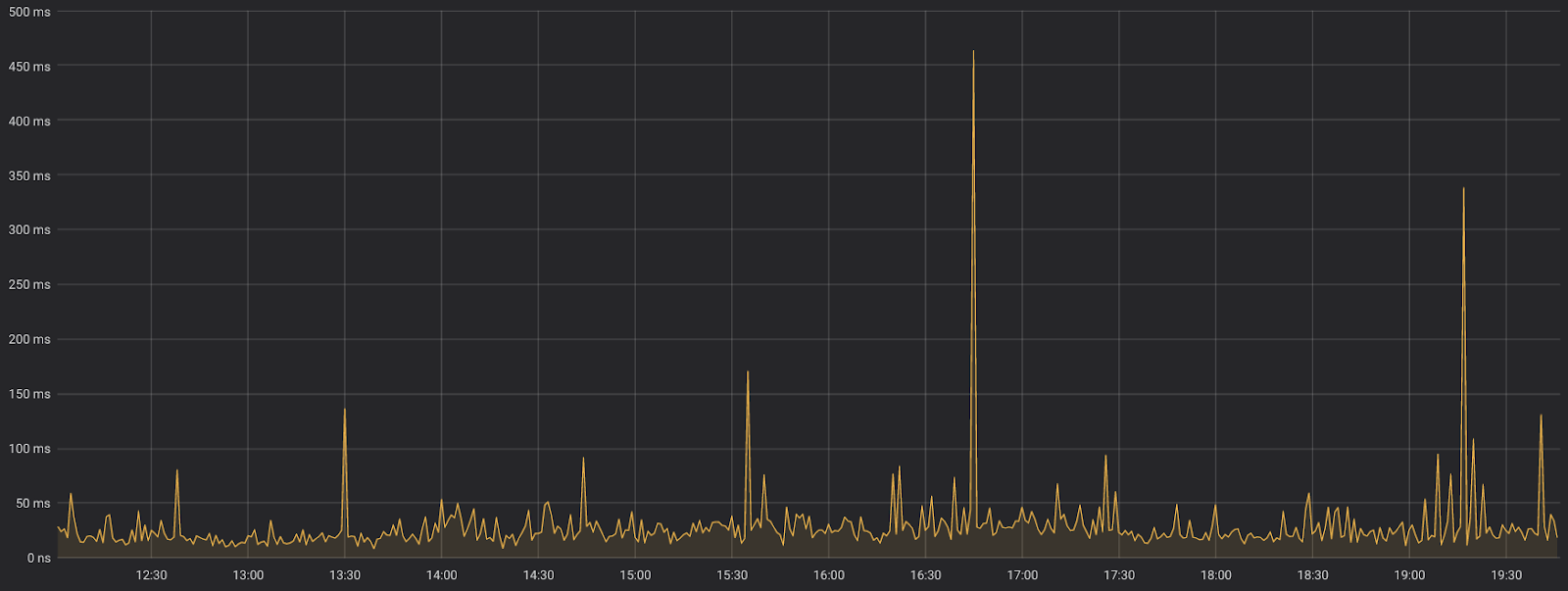
You can clearly see that the baseline response time is around ~20-30 ms. However, we can also see periodic spikes around ~50-100 ms, with peaks up to ~350-450 ms! After a bit of investigation, we concluded that most (although not all) of the spikes were caused by the GC kicking in at the wrong time.
The work I did in the gc-disable branch aims to fix this problem by introducing two new features to the gc module:
It is worth to specify that gc.disable() disables only the major collections, while minor collections still runs. Moreover, thanks to the JIT's virtuals, many objects with a short and predictable lifetime are not allocated at all. The end result is that most objects with short lifetime are still collected as usual, so the impact of gc.disable() on memory growth is not as bad as it could sound.
- gc.disable(), which previously only inhibited the execution of finalizers without actually touching the GC, now disables the GC major collections. After a call to it, you will see the memory usage grow indefinitely.
- gc.collect_step() is a new function which you can use to manually execute a single incremental GC collection step.
Combining these two functions, it is possible to take control of the GC to make sure it runs only when it is acceptable to do so. For an example of usage, you can look at the implementation of a custom GC inside pypytools. The peculiarity is that it also defines a "with nogc():" context manager which you can use to mark performance-critical sections where the GC is not allowed to run.
The following chart compares the behavior of the default PyPy GC and the new custom GC, after a careful placing of nogc() sections:

The yellow line is the same as before, while the purple line shows the new system: almost all spikes have gone, and the baseline performance is about 10% better. There is still one spike towards the end, but after some investigation we concluded that it was not caused by the GC.
Note that this does not mean that the whole program became magically faster: we simply moved the GC pauses in some other place which is not shown in the graph: in this specific use case this technique was useful because it allowed us to shift the GC work in places where pauses are more acceptable.
All in all, a pretty big success, I think. These functionalities are already available in the nightly builds of PyPy, and will be included in the next release: take this as a New Year present :)
Antonio Cuni and the PyPy team
Comments
Could see this being handy for python game libraries too.
I am a bit surprised as these functions have been available for a long time in python gc module. So I suppose the news is a better performing one in pypy?
@samantha: ``gc.collect_step()`` is new.