Leysin Winter sprint
Hi all,
|
The next sprint will be in Leysin, Switzerland, during the week of the 16th-22nd of January 2011. Now that we have released 1.4, and plan to release 1.4.1 soon, the sprint is going to be mainly working on fixing issues reported by various users. Of course this does not prevent people from showing up with a more precise interest in mind. As usual, the break day on the sprint will likely be a day of skiing :-) Hoping to see you there. |

|
Update: there are actually a number of branches that we want to polish and merge into trunk: at least fast-forward, jit-unroll-loops, arm-backend and jitypes2. For more details, see the announcement.
PyPy 1.4 release aftermath
A couple days have passed since the announcement of the 1.4 release, and this is a short summary of what happened afterwards. Let's start with numbers:
- 16k visits to the release announcement on our blog
- we don't have download statistics unfortunately
- 10k visits to speed center
- most traffic comes from referring sites, reddit alone creating above a third of our traffic
Not too bad for a project that doesn't have a well-established user base.
Lessons learned:
- Releases are very important. They're still the major way projects communicate with community, even if we have nightly builds that are mostly stable.
- No segfaults were reported, no incompatibilities between JIT and normal interpretation. We think that proves (or at least provides a lot of experimental evidence) that our write-once-and-then-transform method is effective.
- A lot of people complained about their favorite module in C not working, we should have made it clearer that CPyExt is in alpha state. Indeed, we would like to know which C extension modules do work :-).
- Some people reported massive speedups, other reported slowdowns compared to CPython. Most of those slowdowns relate to modules being inefficient (or doing happy nonsense), like ctypes. This is expected, given that not all modules are even jitted (although having them jitted is usually a matter of a couple of minutes).
- Nobody complained about a lack of some stdlib module. We implemented the ones which are used more often, but this makes us wonder if less used stdlib modules have any users at all.
In general feedback has been overwhelmingly positive and we would like to thank everyone trying (and especially those reporting problems)
Cheers,
fijal
There was a complain about the lack of ssl module by someone trying to use pg8000 with pypy. I wonder if pypy should focus on openssl or on the ssl module.
I'm very impressed with what you've all achieved!
I've been testing PyPy 1.4 with some code I'm working on which only depends on two pure-Python non-stdlib libraries, and although the result was a 50% longer running time than with Python 2.5, it's remarkable that the code behaves in the same way and produces the same results. When trying to produce a fully compatible implementation of something, it's no trivial task to get identical behaviour (even though I'm not really using "exotic" or "frivolous" language features): some corner case usually comes along and makes things difficult. To see a non-trivial example work just like "normal Python" is surely evidence that PyPy is ready for a wider audience.
As for my code, I've been doing some profiling generally - it uses things like the array and bisect modules substantially - and will attempt to see how profile-directed improvements affect PyPy's performance.
Keep up the good work!
A lot of the standard library looks like it has volumes of _legacy_ code depending on it, even if the current bleeding edge people use it less. In my mind supporting essentially all the standard library is a good long term goal, but as pointed out, parts of it can wait. Eventually I would like to see Tkinter support, and I would surmise that it is the most used of the stuff that is not implemented. We use it in a couple items (+/- 10% of total code, not likely to change). I would guess that the situations where these obscure parts of the standard library are being used are the parts were speed is maybe not the most important thing, supporting an existing workflow or parsing legacy data is the key.
@The Cannon Family
The question is why those legacy people would move to PyPy? PyPy is bleeding edge in a way.
Besides a lot of those modules are like audioop or ossaudiodev. I don't see legitimate usecase for those, even in legacy code.
I'm very, very impressed and can't wait to use pypy in a real project. I'm blocked at the moment because I need pyglet on OS X (no MacOS module).
I gave an introduction to cython at the local Python user group and for a lark I ran the original pure-Python code up against the cython version.
cpython: 1.4s
cython: 0.2s
pypy: 0.2s
Hmm :-)
I don't know how it is representative but for this usecase
there is a factor 7 between pypy and cpython 2.7
cpython 2.7
>>> timeit.Timer('sum(x for x in xrange(100000))').repeat(10,100)
[1.3338480523322112, 1.5916376967269201, 1.5959533140645483, 1.8427266639818676,
1.3473615220676294, 1.842070271069737, 1.3346074032759319, 1.5859678554627408,
1.8533299541683306, 1.5872797264355398]
pypy 1.4
>>>> timeit.Timer('sum(x for x in xrange(100000))').repeat(10,100)
[7.5079355199007978, 7.9444552948765477, 7.2710836043080178, 7.5406516611307666,
7.5192312421594352, 7.4927645588612677, 7.5075613773735768, 7.5201248774020826,
7.7839006757141931, 7.5898334809973278]
but maybe it is not representative
We are not heroes, just very patient
Inspired by some of the comments to the release that said "You are heroes", I though a bit about the longish history of PyPy and hunted around for some of the mailing list posts that started the project. Then I put all this information together into the following timeline:
There is also a larger version of the timeline. Try to click on some of the events, the links usually go to the sprint descriptions. I also tried to find pictures for the sprints but succeeded for only half of them, if anybody still has some, I would be interested. It's kind of fun to browse around in some of the old sprint descriptions to see how PyPy evolved. Some of the current ideas have been around for a long time, some are new. In the description of the releases I put estimates for the speed of the release.
Many promising projects bite the dust not due to lack of talent, interest, need or support, but perseverance.
Not only do I believe that pypy has yet to realize it's full potential, I believe that it will actually achieve it. And then some.
So again, keep up the good work!!
p.s
(my flattr account is not yet operational ;-<)
Question,
What do the funds(EU, eurostars) cover?
I see that there had been a burst of activity during the EU period.
Does this mean that funding is a bottleneck to this project? Would the end of the current eurostars funding be an obstacle?
Sure, funding does make a difference. There are couple of people currently (Anto, Armin, Carl Friedrich, partially Maciej, me ...) who get some money through the Eurostars project. This does make a difference in terms of how much time can be devoted. I guess there should be a clarifying blog post on this and maybe also some opinions and views on how things can continue after the funding period (which ends second half next year).
Amazing how far you have come. Congrats!
I found myself in 3 of those old sprint pictures, and I remember all of them as very good times that overall probably taught me more than the school I was attending during that time.
This timeline sort of makes the point. You are heroes ;). Patience is harder than a few nights of crazy hacking and brilliant ideas.
Yeah, you have more heroic patience than I tended to display
cheerleading/criticizing the project.
Currently there's nothing left to criticize for me -- I think everything's being done pretty much right (communication, releases, even work on C-module support!).
But that might change once I start to use the project seriously. :)
PyPy 1.4: Ouroboros in practice
We're pleased to announce the 1.4 release of PyPy. This is a major breakthrough in our long journey, as PyPy 1.4 is the first PyPy release that can translate itself faster than CPython. Starting today, we are using PyPy more for our every-day development. So may you :) You can download it here:
https://pypy.org/download.html
What is PyPy
PyPy is a very compliant Python interpreter, almost a drop-in replacement for CPython. It is fast (pypy 1.4 and cpython 2.6 comparison).
New Features
Among its new features, this release includes numerous performance improvements (which made fast self-hosting possible), a 64-bit JIT backend, as well as serious stabilization. As of now, we can consider the 32-bit and 64-bit linux versions of PyPy stable enough to run in production.
Numerous speed achievements are described on our blog. Normalized speed charts comparing pypy 1.4 and pypy 1.3 as well as pypy 1.4 and cpython 2.6 are available on the benchmark website. For the impatient: yes, we got a lot faster!
More highlights
- PyPy's built-in Just-in-Time compiler is fully transparent and automatically generated; it now also has very reasonable memory requirements. The total memory used by a very complex and long-running process (translating PyPy itself) is within 1.5x to at most 2x the memory needed by CPython, for a speed-up of 2x.
- More compact instances. All instances are as compact as if they had __slots__. This can give programs a big gain in memory. (In the example of translation above, we already have carefully placed __slots__, so there is no extra win.)
- Virtualenv support: now PyPy is fully compatible with virtualenv: note that to use it, you need a recent version of virtualenv (>= 1.5).
- Faster (and JITted) regular expressions - huge boost in speeding up the re module.
- Other speed improvements, like JITted calls to functions like map().
Cheers,
Carl Friedrich Bolz, Antonio Cuni, Maciej Fijalkowski,
Amaury Forgeot d'Arc, Armin Rigo and the PyPy team
all I want for Christmas is stackless support in a 64-bit pypy-c-jit :) 'two greenlets switching and a partridge in a pear tree!'
Congratulations. I hope the PPA is going to be updated soon. Too lazy to build it myself, right now. (:
Is there a -j <number-of-cores> option for the translation process? It's a bit unfortunate that 15 cores on the nice machine I'm using can't be put to use making it translate faster. (Or unfortunate that I didn't read the documentation, maybe.)
The report of 2.4GB usage on x86-64 is accurate, but it took about 7800s on a 2.33GHz Xeon. Next time I'll try and exercise some of the other cores, though.
so pypy on average is now about 2x faster than cpython?
and unladen swallows goal was being 5x faster? was that totally unrealistic?
Does this release include the -free branch that was mentioned in the previous post? The 2x memory requirements lead me to believe so.
@Daivd
yes, it does
@Anonymous
5x improvement is not a well defined goal, however it's a good marketing thing. PyPy is 2x faster on translation, 60x faster on some benchmarks while slower on other. What does it mean to be 5x faster?
Do you know why the purely numerical benchmarks nbody and spectral-norm are still so much slower in PyPy compared to e.g. LuaJIT?
This is awesome. PyPy 1.4 addresses the 2 slowest benchmarks, slowspitfire and spambayes. There is no benchmark anymore where PyPy is much slower than CPython.
To me, this marks the first time you can say that PyPy is ready for general "consumption". Congratulations!
PS: The best comparison to appreciate how much of an improvement 1.4 has been is:
https://speed.pypy.org/comparison/?exe=2%2B35,1%2B41,1%2B172&ben=1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20&env=1&hor=false&bas=2%2B35&chart=normal+bars
@scientist
Sure, because LuaJIT is crazy when it comes to optimizations :-) We'll get there eventually, but purely numerical stuff is not as high on our list as other things.
@maciej: in an old thread (have tracing compilers won?) you replied to Mike Pall saying that pypy was in a way middle ground, that it didn't offer as much opportunities for micro optimizations as luajit.
You were discussing about keeping high level constructions from the user program to perform more tricks.
Has the situation changed?
Do you really think now that you'll get there?
Anyway, let me tell you that you are all already my super heroes :-)
Heh, I don't remember that :-)
Anyway, LuaJIT has more options for microoptimziations simply because Lua is a simpler language. That doesn't actually make it impossible for PyPy, it simply make it harder and taking more time (but it's still possible). I still think we can get (but predicting future is hard) where LuaJIT is right now, but racing Mike would be a challenge that we might loose ;-)
That said, even in simple loops there are obvious optimizations to be performed, so we're far from being done. We're going there, but it's taking time ;-)
Congrats to all PyPy developers for making huge contributions to Python performance, JIT and implementation research and delivering an end product that will help many developers to get more done.
IIUC, we still have ARM, jit-unroll-loops, more memory improvements, Python 2.7 (Fast Forward branch) and a bunch of other cool improvements in the works, besides some known interesting targets that will eventually be tackled (e.g. JITted stackless).
I wish more big Python apps and developers would play with PyPy and report the results.
Cheers!
P.S.: Fijal: see https://lambda-the-ultimate.org/node/3851#comment-57715
Congratulations.
However, you suggest people used it in production environment - please, give us version compatible at least with CPython 2.6.
I hope that you plan it but at first you wanted to have stable and fast base. :)
@Michal:
There is already an ongoing effort to port PyPy to Python 2.7.
But we need some help! It's a good way to become a PyPy developer.
And no, you don't have to be a JIT expert to implement itertools.combinations or asian codecs.
Improving Memory Behaviour to Make Self-Hosted PyPy Translations Practical
In our previous blog post, we talked about how fast PyPy can translate itself compared to CPython. However, the price to pay for the 2x speedup was an huge amount of memory: actually, it was so huge that a standard -Ojit compilation could not be completed on 32-bit because it required more than the 4 GB of RAM that are addressable on that platform. On 64-bit, it consumed 8.3 GB of RAM instead of the 2.3 GB needed by CPython.
This behavior was mainly caused by the JIT, because at the time we wrote the blog post the generated assembler was kept alive forever, together with some big data structure needed to execute it.
In the past two weeks Anto and Armin attacked the issue in the jit-free branch, which has been recently merged to trunk. The branch solves several issues. The main idea of the branch is that if a loop has not been executed for a certain amount of time (controlled by the new loop_longevity JIT parameter) we consider it "old" and no longer needed, thus we deallocate it.
(In the process of doing this, we also discovered and fixed an oversight in the implementation of generators, which led to generators being freed only very slowly.)
To understand the freeing of loops some more, let's look at how many loops are actually created during a translation. The purple line in the following graph shows how many loops (and bridges) are alive at any point in time with an infinite longevity, which is equivalent to the situation we had before the jit-free branch. By contrast, the blue line shows the number of loops that you get in the current trunk: the difference is evident, as now we never have more than 10000 loops alive, while previously we got up to about 37000 ones. The time on the X axis is expressed in "Giga Ticks", where a tick is the value read out of the Time Stamp Counter of the CPU.

The grey vertical bars represent the beginning of each phase of the translation:
- annotate performs control flow graph construction and type inference.
- rtype lowers the abstraction level of the control flow graphs with types to that of C.
- pyjitpl constructs the JIT.
- backendopt optimizes the control flow graphs.
- stackcheckinsertion finds the places in the call graph that can overflow the C stack and inserts checks that raise an exception instead.
- database_c produces a database of all the objects the C code will have to know about.
- source_c produces the C source code.
- compile_c calls the compiler to produce the executable.
You can nicely see, how the number of alive graphs drops shortly after the beginning of a new phase.
Those two fixes, freeing loops and generators, improve the memory usage greatly: now, translating PyPy on PyPy on 32-bit consumes 2 GB of RAM, while on CPython it consumes 1.1 GB. This result can even be improved somewhat, because we are not actually freeing the assembler code itself, but only the large data structures around it; we can consider it as a residual memory leak of around 150 MB in this case. This will be fixed in the jit-free-asm branch.
The following graph shows the memory usage in more detail:
- the blue line (cpython-scaled) shows the total amount of RAM that the OS allocates for CPython. Note that the X axis (the time) has been scaled down so that it spans as much as the PyPy one, to ease the comparison. Actually, CPython took more than twice as much time as PyPy to complete the translation
- the red line (VmRss) shows the total amount of RAM that the OS allocates for PyPy: it includes both the memory directly handled by our GC and the "raw memory" that we need to allocate for other tasks, such as the assembly code generated by the JIT
- the brown line (gc-before) shows how much memory is used by the GC before each major collection
- the yellow line (gc-after) shows how much memory is used by the GC after each major collection: this represent the amount of memory which is actually needed to hold our Python objects. The difference between gc-before and gc-after (the GC delta) is the amout of memory that the GC uses before triggering a new major collection

By comparing gc-after and cpython-scaled, we can see that PyPy uses mostly the same amount of memory as CPython for storing the application objects (due to reference counting the memory usage in CPython is always very close to the actually necessary memory). The extra memory used by PyPy is due to the GC delta, to the machine code generated by the JIT and probably to some other external effect (such as e.g. Memory Fragmentation).
Note that the GC delta can be set arbitrarly low (another recent addition -- the default value depends on the actual RAM on your computer; it probably works to translate if your computer has precisely 2 GB, because in this case the GC delta and thus the total memory usage will be somewhat lower than reported here), but the cost is to have more frequent major collections and thus a higher run-time overhead. The same is true for the memory needed by the JIT, which can be reduced by telling the JIT to compile less often or to discard old loops more frequently. As often happens in computer science, there is a trade-off between space and time, and currently for this particular example PyPy runs twice as fast as CPython by doubling the memory usage. We hope to improve even more on this trade-off.
On 64-bit, things are even better as shown by the the following graph:

The general shape of the lines is similar to the 32-bit graph. However, the relative difference to CPython is much better: we need about 3 GB of RAM, just 24% more than the 2.4 GB needed by CPython. And we are still more than 2x faster!
The memory saving is due (partly?) to the vtable ptr optimization, which is enabled by default on 64-bit because it has no speed penalty (see Unifying the vtable ptr with the GC header).
The net result of our work is that now translating PyPy on PyPy is practical and takes less than 30 minutes. It's impressive how quickly you get used to translation taking half the time -- now we cannot use CPython any more for that because it feels too slow :-).
Big huge improvement since last post. Kudos!! :-)
Please don't get me wrong, but I need to ask: is there any plan to merge pypy into cPython (or even replace it)?
BTW, I'm following the blog (please, keep this regular posts) and planing to make a donation to support your next sprint due to the regular and very well done work.
congratulations again.
This is amazing. It was kind of a let down when you reported it used too much memory. But now I can on my laptop translate pypy in 32 and 64 bits using pypy itself :)
The world is good again :)
@crncosta
There are no plans for merging PyPy to CPython. I don't think "replacing" is a good word, but you can use PyPy for a lot of things already, so it is a viable Python implementation together with CPython.
I am curious... Has there ever been interest from Google to sponsor this project?
I know about unladen swallow, but has anyone there expressed interest in using pypy somewhere in their organization?
Sorry for the off topic question...
Always fascinating to read about the work you're doing. Please keep posting, and keep up the good work. You really are heroes.
Wow! this is great news.. keep us posted on what other developments you have.
like luis i am also curious about why google doesn't show a lot more interest in pypy. unladen swallow didn't really work out or did it?
Running large radio telescope software on top of PyPy and twisted
Hello.
As some of you already know, I've recently started working on a very large radio telescope at SKA South Africa. This telescope's operating software runs almost exclusively on Python (several high throughput pieces are in C or CUDA or directly executed by FPGAs). Some cool telescope pictures:


(photos courtesy of SKA South Africa)
Most of the operation software is using the KatCP protocol to talk between devices. The currently used implementation is Open Source software with a custom home built server and client. As part of the experiments, I've implemented a Twisted based version and run in on top of CPython and PyPy for both the default implementation and the one based on Twisted to see how those perform.
There are two testing scenarios: the first one is trying to saturate the connection by setting up multiple sensors that report state every 10ms, the second one is measuring a round-trip between sending a request and receiving the response. Both numbers are measuring the number of requests per 0.2s, so the more the better. On X axis there is a number of simultanously connected clients.
All benchmark code is available in the KatCP repository.
The results are as follows:


As you can see, in general Twisted has larger overhead for a single client and scales better as the number of clients increases. That's I think expected, since Twisted has extra layers of indirection. The round trip degradation of Twisted has to be investigated, but for us scenario1 is by far more important.
All across the board PyPy performs much better than CPython for both Twisted and a home-made solution, which I think is a pretty good result.
Note: we didn't roll this set up into production yet, but there are high chances for both twisted and PyPy to be used in some near future.
Cheers, fijal
Why not try PyZmq (https://www.zeromq.org/bindings:python):)? the IPython project(https://ipython.scipy.org/moin/) is also moving from Twisted
to PyZmq.
Sorry this is not an apropriate forum to discuss this. One of the reasons would be that Twisted and PyZmq are doing two completely different things and PyZmq won't work on PyPy.
Oh, I envy you. And congratulations.
Keep working.
I wait for 2.6 compatible ver. of PyPy to try it with my little project.
A widząc, że prawdopodobnie rodak, to tym bardziej się cieszę.
Maciej, this is great news. Congratulations.
I look forward to making PyPy+Twisted even faster from the Twisted side :).
Hi Maciej,
You say that there you are mostly using Python and sometimes C, CUDA or FPGAs.
I am writing my master thesis in the Netherlands, it is about the efficient implementation of a beam forming algorithm (the one used by the LOFAR) on modern GPUs using CUDA and OpenCL. Do you have some papers or other material there about the telescope software ? I would be really interested on citing it on the related works part.
Hey Alessio. I think this blog is not really a good medium for 2-way communication feel free to come to #pypy on irc.freenode.net or write to me directly at fijall at gmail.
In general, we don't want beam forming to be performed on GPU (because it's hard), but rather on custom-built hardware and FPGAs.
I have a program using Python and Twisted where I load tested both server and client connections (the program can do both the server and client protocol). I tested both types out to 100 connections (at 50 milli-second polling intervals) while measuring CPU load.
What I found was that when acting as a server it scaled fairly linearly. When acting as the client side however, load rose to a peak about 60 clients, then fell by a third until 80 clients, and then rose again until at 100 clients it reached the same load level as at 60. If you have a similar situation you may need to watch out for this phenomenon.
I also found that using the epoll reactor on Linux made a *big* difference to capacity in my applications, much more so than any normal program optimization efforts that I made. I have multiple clients and multiple server ports all running simultaneously, so I'm not sure how this may translate to your application if you are only using Twisted as a server.
Here's a link to my project web site where I show the connections versus CPU load chart (first chart):
https://mblogic.sourceforge.net/mblogichelp/general/Capacity-en.html
I haven't tested this with PyPy as I don't have a combination of anything that is both 32-bit *and* new enough to run a recent version.
I also made the previous anonymous post on the 21st. I haven't been able to get the 64 bit JIT version to run or build. That may be my fault, but I haven't been able to test it (this isn't a problem that I want to waste your time on however).
I have tested the non-JIT Pypy using a simplified version of my server and client programs, using asyncore instead of Twisted. The server and client use a standard industrial automation protocol to talk to each other over a TCP socket. The programs also make heavy use of list slicing and struct.
The non-JIT version passes all the tests I have for the server, and runs my application performance test at roughly 1/3 the speed of CPython 2.6. This is very impressive, as I have never been able to get either IronPython (on Mono) nor Jython to even run the programs, let alone pass my functional tests. The fact that Pypy (non-JIT) can run these programs perfectly without changes is something that I find very promising.
Please continue the good work, and thank you for what you've done so far!
Hey, great to hear!
Well, the non-JIT version would rather be slow, but that's fine :) We try very hard to produce a compliant python interpreter and twisted folk helped us greatly with getting all the posix stuff right.
Cheers,
fijal
Efficiently Implementing Python Objects With Maps
As could be foreseen by my Call for Memory Benchmarks post a while ago, I am currently working on improving the memory behaviour of PyPy's Python interpreter. In this blog post I want to describe the various data a Python instance can store. Then I want to describe how a branch that I did and that was recently merged implements the various features of instances in a very memory-efficient way.
Python's Object Model
All "normal" new-style Python instances (i.e. instances of subclasses of object without added declarations) store two (or possibly three) kinds of information.
Storing the Class
Every instance knows which class it belongs to. This information is accessible via the .__class__ attribute. It can also be changed to other (compatible enough) classes by writing to that attribute.
Instance Variables
Every instance also has an arbitrary number of attributes stored (also called instance variables). The instance variables used can vary per instance, which is not the case in most other class-based languages: traditionally (e.g. in Smalltalk or Java) the class describes the shape of its instances, which means that the set of admissible instance variable names is the same for all instances of a class.
In Python on the other hand, it is possible to add arbitrary attributes to an instance at any point. The instance behaves like a dictionary mapping attribute names (as strings) to the attribute values.
This is actually how CPython implements instances. Every instance has a reference to a dictionary that stores all the attributes of the instance. This dictionary can be reached via the .__dict__ attribute. To make things more fun, the dictionary can also be changed by writing to that attribute.
Example
As an example, consider the following code:
class A(object):
pass
instance1 = A()
instance1.x = 4
instance1.y = 6
instance1.z = -1
instance2 = A()
instance2.x = 1
instance2.y = 2
instance2.z = 3
These two instances would look something like this in memory:

(The picture glosses over a number of details, but it still shows the essential issues.)
This way of storing things is simple, but unfortunately rather inefficient. Most instances of the same class have the same shape, i.e. the same set of instance attribute names. That means that the key part of all the dictionaries is identical (shown grey here). Therefore storing that part repeatedly in all instances is a waste. In addition, dictionaries are themselves rather large. Since they are typically implemented as hashmaps, which must not be too full to be efficient, a dictionary will use something like 6 words on average per key.
Slots
Since normal instances are rather large, CPython 2.2 introduced slots, to make instances consume less memory. Slots are a way to fix the set of attributes an instance can have. This is achieved by adding a declaration to a class, like this:
class B(object):
__slots__ = ["x", "y", "z"]
Now the instances of B can only have x, y and z as attributes and don't have a dictionary at all. Instead, the instances of B get allocated with enough size to hold exactly the number of instance variables that the class permits. This clearly saves a lot of memory over the dictionary approach, but has a number of disadvantages. It is obviously less flexible, as you cannot add additional instance variables to an instance if you happen to need to do that. It also introduces a set of rules and corner-cases that can be surprising sometimes (e.g. instances of a subclass of a class with slots that doesn't have a slots declaration will have a dict).
Using Maps for Memory-Efficient Instances
As we have seen in the diagram above, the dictionaries of instances of the same class tend to look very similar and share all the keys. The central idea to use less memory is to "factor out" the common parts of the instance dictionaries into a new object, called a "map" (because it is a guide to the landscape of the object, or something). After that factoring out, the representation of the instances above looks something like this:

Every instance now has a reference to its map, which describes what the instance looks like. The actual instance variables are stored in an array (called storage in the diagram). In the example here, the map describes that the instances have three attributes x, y and z. The numbers after the attributes are indexes into the storage array.
If somebody adds a new attribute to one of the instances, the map for that instance will be changed to another map that also contains the new attribute, and the storage will have to grow a field with the new attribute. The maps are immutable, immortal and reused as much as possible. This means, that two instances of the same class with the same set of attributes will have the same map. This also means that the memory the map itself uses is not too important, because it will potentially be amortized over many instances.
Note that using maps makes instances nearly as small as if the correct slots had been declared in the class. The only overhead needed is the indirection to the storage array, because you can get new instance variables, but not new slots.
The concept of a "map" that describes instances is kind of old and comes from the virtual machine for the Self programming language. The optimization was first described in 1989 in a paper by Chambers, Ungar and Lee with the title An Efficient Implementation of Self, a Dynamically-Typed Object-Oriented Language Based on Prototypes. A similar technique is used in Google's V8 JavaScript engine, where the maps are called hidden classes and in the Rhino JavaScript engine.
The rest of the post describes a number of further details that occur if instances are implemented using maps.
Supporting Dictionaries with Maps
The default instance representation with maps as shown above works without actually having a dictionary as part of each instance. If a dictionary is actually requested, by accessing the .__dict__ attribute, it needs to be created and cached. The dictionary is not a normal Python dictionary, but a thin wrapper around the object that forwards all operations to it. From the user's point of view it behaves like a normal dictionary though (it even has the correct type).
The dictionary needs to be cached, because accessing .__dict__ several times should always return the same dictionary. The caching happens by using a different map that knows about the dictionary and putting the dictionary into the storage array:

Things become really complex if the fake dict is used in strange ways. As long as the keys are strings, everything is fine. If somebody adds other keys to the dict, they cannot be represented by the map any more (which supports only attributes, i.e. string keys in the __dict__). If that happens, all the information of the instance will move into the fake dictionary, like this:
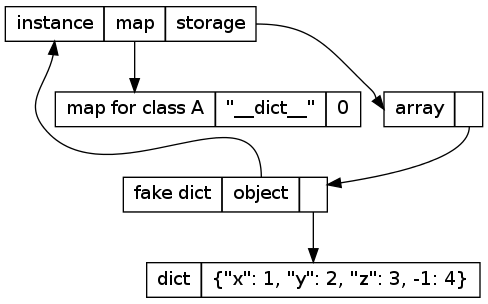
In this picture, the key -1 was added to the instance's dictionary. Since using the dictionary in arbitrary ways should be rare, we are fine with the additional time and memory that the approach takes.
Slots and Maps
Maps work perfectly together with slots, because the slots can just be stored into the storage array used by the maps as well (in practise there are some refinements to that scheme). This means that putting a __slots__ on a class has mostly no effect, because the instance only stores the values of the attributes (and not the names), which is equivalent to the way slots are stored in CPython.
Implementation Details
In the diagrams above, I represented the maps as flat objects. In practise this is a bit more complex, because it needs to be efficient to go from one map to the next when new attributes are added. Thus the maps are organized in a tree.
The instances with their maps from above look a bit more like this in practise:

Every map just describes one attribute of the object, with a name and a an index. Every map also has a back field, that points to another map describing what the rest of the object looks like. This chain ends with a terminator, which also stores the class of the object.
The maps also contain the information necessary for making a new object of class A. Immediately after the new object has been created, its map is the terminator. If the x attribute is added, its maps is changed to the second-lowest map, and so on. The blue arrows show the sequence of maps that the new object goes through when the attributes x, y, z are added.
This representation of maps as chains of objects sounds very inefficient if an object has many attributes. The whole chain has to be walked to find the index. This is true to some extent. The problem goes away in the presence of the JIT, which knows that the chain of maps is an immutable structure, and will thus optimize away all the chain-walking. If the JIT is not used, there are a few caches that try to speed up the walking of this chain (similar to the method cache in CPython and PyPy).
Results
It's hard to compare the improvements of this optimization in a fair way, as the trade-offs are just very different. Just to give an impression, a million objects of the same class with three fields on a 32bit system takes:
without slots:
- 182 MiB memory in CPython
- 177 MiB memory in PyPy without maps
- 40 MiB memory in PyPy with maps
with slots:
- 45 MiB memory in CPython
- 50 MiB memory in PyPy without maps
- 40 MiB memory in PyPy with maps
Note how maps make the objects a bit more efficient like CPython using slots. Also, using slots has no additional effect in PyPy.
Conclusion
Maps are a powerful approach to shrinking the memory used by many similar instances. I think they can be pushed even further (e.g. by adding information about the types of the attributes) and plan to do so in the following months. Details will be forthcoming.
Not sure if you are glossing over this, but it seems trivial to avoid the map chain walking by duplicating all of the information in a maps back pointer chain into the map itself. However, the lookup keys are still strings, so your options are some kind of frozen hashtable (which could be nice) or a sorted array.
Both of those still seem much more efficient than chasing pointers.
I was surprised not to see any real-world benchmarks (since you collected them earlier). That leaves the impression, that it might be disapointing (knowing that the object/class ratio generally isn't very large).
@Reid:
I am glossing over the runtime overhead, because the JIT completely removes it, as it knows that the maps are immutable. So you only have a problem if you don't want a JIT, in which case maps indeed make some things a bit slower. Duplicating the information everywhere is possible, but I would like to avoid it (we had a prototype that did it, and it became messy quickly).
@Erez
There is no additional runtime overhead if you have the JIT – in fact, things become faster, because the JIT can turn an attribute access into a array field read out of the storage array at a fixed offset.
@Anonymous
I have not presented any real-world benchmarks, because I actually did not get around to running them. Yes, I collected some and started writing a memory benchmark framework. But I didn't have time for a full analysis yet. I plan to do such an analysis hopefully soon.
Anyway, maps never make anything larger, so it is really just a matter of how many instances there are in practice. This will just depend on the benchmark.
Does this optimization enable building pypy using pypy without having 16GB of ram?
Is there anything intrinsic toPyPy in this, or can this optimisation be used in CPython as well?
To remove the chain-walking overhead when the code is not JITted, would it be possible to use a persistent hashtable, like for example the hash trie used in Clojure (see https://blog.higher-order.net/2009/09/08/understanding-clojures-persistenthashmap-deftwice/)? They are quite simple to implement and very fast (almost as fast as a normal hashtable lookup)
ot: i'm part way to implementing that for Python.
https://bazaar.launchpad.net/~washort/%2Bjunk/perseus/annotate/head:/perseus/__init__.py
@Allen: interesting, I wonder how much code would need to be changed to make it RPython...
What are the pypy "with slots" and "without slots" numbers? They are different even though you point out that they have no effect. Is the pypy in question one with sharing dicts?
@verte mapdicts help pypy objects with or without slots (although much more for the latter). There is no difference in pypy with mapdict between having slots or not having slots.
@Zeev no, the translation results from last week already included this optimization. Maps don't help translation much, because we already added all the necessary slot declarations to save memory on CPython.
@ot Would be possible, yes. Not sure it is worth it, given that the total set of attributes of typical instances is not very large. The data structure looks interesting though.
@Carl: yes, it was just hypotetic, "if it is a bottleneck". I think anyway that even with very small instance dictionaries there could be a benefit: most keys would be resolved within the first layer of the trie, so with a single lookup or two at most. But it could be premature optimization.
I still don't understand. Was there a difference with __slots__ on pypy before mapdict? Why are the numbers different on pypy without mapdict? Are those the numbers with or without the old sharing dictimpl? If without, what is the memory usage with sharing dicts?
This came up on StackOverflow, but let me answer it here.
While the CPython split-dict implementation in 3.3+ (PEP 412) may be inspired by your design, it's not the same, and it doesn't provide nearly as much savings.
The first difference is that it still has a full dict struct in the instance. For classes without that many attributes (i.e., most of them), the dict struct is almost as big as the hash table, so this means you typically only get half the savings as in PyPy. However, this means the thing you can access by __dict__ isn't created dynamically, it acts exactly like a dict even at the C API level, and it can transparently (again, even at the C API level) convert itself to a combined dict if needed (if the table needs to expand and there's more than one reference to the shared key table). The fact that the difference between 3.2 and 3.3 is completely undetectable to any code that doesn't directly access the hash buckets is a big part of the reason Mark Shannon was able to get everyone to agree to accept it, and as far as I know there's no serious consideration for changing it.
The second difference is that the dict struct's array is kept in the same (sparse) order as the shared key table, rather than being a compact array indexed by the values of the shared key table. This means it's kept at least 1/3rd unloaded, meaning that again you get less space savings than with PyPy. There's less of a good rationale here; there's a small performance cost to the slightly more complicated code needed for indexing PyPy-style, and it would make small combined dicts one word larger (which could affect classes whose instances all have different attributes, or cases where you have a huge number of classes with few instances, or other edge cases). The PEP implies that using the sparse implementation is probably overly conservative, and leaves open the possibility of changing it after 3.3.
Speeding up PyPy by donations
PyPy joins the Software Freedom Conservancy
Good news. PyPy is now a member of the Software Freedom Conservancy (SFC), see the SFC blog post. This allows us to manage non-profit monetary aspects of the project independently from a company or particular persons. So we can now officially receive donations both from people prefering right or left sides, see the Donate buttons on our home page and our blog. And you can use PayPal or Google Checkout, Donations are tax-exempt in the USA and hopefully soon in Europe as well.
What's it going to get used for? For the immediate future we intend to use the donations for funding travels of core contributors to PyPy sprints who otherwise can't afford to come. So if you have no time but some money you can help to encourage coding contributors to care for PyPy. If we end up with bigger sums we'll see and take suggestions. Money spending decisions will be done by core PyPy people according to non-profit guidelines. And we'll post information from time to time about how much we got and where the money went.
If you have any questions regarding the SFC membership or donations you may send email to sfc at pypy.org which will be observed by Carl Friedrich Bolz, Jacob Hallen and Holger Krekel - the initial PyPy SFC representatives on behalf of the PyPy team. Many thanks go out to Bradley M. Kuhn for helping to implement the PyPy SFC membership.
cheers,
Holger & Carl Friedrich
Congratulations, welcome to the SFC family! It's been great for Twisted. Just donated $25 myself - now go make Twisted faster on PyPy :).
Thanks glyph. I realized we should have mentioned Twisted already in the post since you are working through the SFC for some time now. In fact, your being there was a good argument for us to also consider going there, so thanks for that :)
A snake which bites its tail: PyPy JITting itself

We have to admit: even if we have been writing for years about the fantastic speedups that the PyPy JIT gives, we, the PyPy developers, still don't use it for our daily routine. Until today :-).
Readers brave enough to run translate.py to translate PyPy by themselves surely know that the process takes quite a long time to complete, about a hour on super-fast hardware and even more on average computers. Unfortunately, it happened that translate.py was a bad match for our JIT and thus ran much slower on PyPy than on CPython.
One of the main reasons is that the PyPy translation toolchain makes heavy use of custom metaclasses, and until few weeks ago metaclasses disabled some of the central optimizations which make PyPy so fast. During the recent Düsseldorf sprint, Armin and Carl Friedrich fixed this problem and re-enabled all the optimizations even in presence of metaclasses.
So, today we decided that it was time to benchmark again PyPy against itself. First, we tried to translate PyPy using CPython as usual, with the following command line (on a machine with an "Intel(R) Xeon(R) CPU W3580 @ 3.33GHz" and 12 GB of RAM, running a 32-bit Ubuntu):
$ python ./translate.py -Ojit targetpypystandalone --no-allworkingmodules ... lots of output, fractals included ... [Timer] Timings: [Timer] annotate --- 252.0 s [Timer] rtype_lltype --- 199.3 s [Timer] pyjitpl_lltype --- 565.2 s [Timer] backendopt_lltype --- 217.4 s [Timer] stackcheckinsertion_lltype --- 26.8 s [Timer] database_c --- 234.4 s [Timer] source_c --- 480.7 s [Timer] compile_c --- 258.4 s [Timer] =========================================== [Timer] Total: --- 2234.2 s
Then, we tried the same command line with PyPy (SVN revision 78903, x86-32 JIT backend, downloaded from the nightly build page):
$ pypy-c-78903 ./translate.py -Ojit targetpypystandalone --no-allworkingmodules ... lots of output, fractals included ... [Timer] Timings: [Timer] annotate --- 165.3 s [Timer] rtype_lltype --- 121.9 s [Timer] pyjitpl_lltype --- 224.0 s [Timer] backendopt_lltype --- 72.1 s [Timer] stackcheckinsertion_lltype --- 7.0 s [Timer] database_c --- 104.4 s [Timer] source_c --- 167.9 s [Timer] compile_c --- 320.3 s [Timer] =========================================== [Timer] Total: --- 1182.8 s
Yes, it's not a typo: PyPy is almost two times faster than CPython! Moreover, we can see that PyPy is faster in each of the individual steps apart compile_c, which consists in just a call to make to invoke gcc. The slowdown comes from the fact that the Makefile also contains a lot of calls to the trackgcroot.py script, which happens to perform badly on PyPy but we did not investigate why yet.
However, there is also a drawback: on this specific benchmark, PyPy consumes much more memory than CPython. The reason why the command line above contains --no-allworkingmodules is that if we include all the modules the translation crashes when it's complete at 99% because it consumes all the 4GB of memory which is addressable by a 32-bit process.
A partial explanation if that so far the assembler generated by the PyPy JIT is immortal, and the memory allocated for it is never reclaimed. This is clearly bad for a program like translate.py which is divided into several independent steps, and for which most of the code generated in each step could be safely be thrown away when it's completed.
If we switch to 64-bit we can address the whole 12 GB of RAM that we have, and thus translating with all working modules is no longer an issue. This is the time taken with CPython (note that it does not make sense to compare with the 32-bit CPython translation above, because that one does not include all the modules):
$ python ./translate.py -Ojit [Timer] Timings: [Timer] annotate --- 782.7 s [Timer] rtype_lltype --- 445.2 s [Timer] pyjitpl_lltype --- 955.8 s [Timer] backendopt_lltype --- 457.0 s [Timer] stackcheckinsertion_lltype --- 63.0 s [Timer] database_c --- 505.0 s [Timer] source_c --- 939.4 s [Timer] compile_c --- 465.1 s [Timer] =========================================== [Timer] Total: --- 4613.2 s
And this is for PyPy:
$ pypy-c-78924-64 ./translate.py -Ojit [Timer] Timings: [Timer] annotate --- 505.8 s [Timer] rtype_lltype --- 279.4 s [Timer] pyjitpl_lltype --- 338.2 s [Timer] backendopt_lltype --- 125.1 s [Timer] stackcheckinsertion_lltype --- 21.7 s [Timer] database_c --- 187.9 s [Timer] source_c --- 298.8 s [Timer] compile_c --- 650.7 s [Timer] =========================================== [Timer] Total: --- 2407.6 s
The results are comparable with the 32-bit case: PyPy is still almost 2 times faster than CPython. And it also shows that our 64-bit JIT backend is as good as the 32-bit one. Again, the drawback is in the consumed memory: CPython used 2.3 GB while PyPy took 8.3 GB.
Overall, the results are impressive: we knew that PyPy can be good at optimizing small benchmarks and even middle-sized programs, but as far as we know this is the first example in which it heavily optimizes a huge, real world application. And, believe us, the PyPy translation toolchain is complex enough to contains all kinds of dirty tricks and black magic that make Python lovable and hard to optimize :-).
This is amazing, huge kudos to all PyPy developers!
Do these results include "Håkan's jit-unroll-loops branch" you mentioned in sprint report? When are we going to get a release containing these improvements? And do the nightly builds include them?
@Victor: No, Håkan's branch has not been merged. It still has some problems that we don't quite know how to solve.
The nightly builds include all other improvements though. We plan to do a release at some point soon.
This is great!
One question: A while back, after the GSoC project for 64-bit, there was an issue with asmgcc-64 such that the 64-bit GC was slower than it should be.
It appears from the performance described in this post, that that must be resolved now. Is that right?
Thanks,
Gary
There should be a way to not only throw away jit memory but somehow tell pypy to try to not use more than say 3gb of ram so it will not hit swap on 4gb machines.
Wow, looks great!
Many thanks for posting the benchmark – and for your relentless work on pypy!
One thing: Could you add tests comparing with programs converted to python3?
@ArneBab: I'm not sure what you mean, but consider that at the moment PyPy does not support Python 3, so it does not make sense to compare against it.
For reference, at some point (long ago) I tried to use Psyco to speed up translate.py on CPython; but i didn't make any difference -- I'm guessing it's because we have nested scope variables at a few critical points, which Psyco cannot optimize. Now I no longer have a need for that :-)
Very cool achievement. I'm curious however to know why compile_c section is slower. I thought it was mostly waiting on external programs to run and so should of been similar time cpython? Congratulations!
@Anonymous: you are right when you say that compile_c mostly invokes gcc, but also a python script called trackgcroot.py.
The python script is run with the same interpreter using for translate.py (so pypy in this case), and it happens that it's slower than with cpython.
How come the 64 bit timings are so much worse than the 32 bit timings (both CPython and PyPy)?
@Anonymous: Because the 64bit version is translating all modules, which simply gives the translator a lot more to do. We cannot do that yet on 32bit due to memory problems.
@cfbolz Well, but you sure can run the 64bit version with the same module list as you did for 32bit... So if running the benchmark again in the same conditions isn't a lot of work, it'd provide yet another interesting data point ;)
In other words: The pypy jit compiler leaks a massive amount of memory. Will you address this issue?
Technically it's not "leaking". And yes, we're trying to address this issue.
Yes I think the word you wanted was "uses" instead of "leaks". The latter implies unforseen problems and errors, the former implies that memory usage hasn't been addressed yet... Just to reiterate - PyPy currently *uses* more memory than CPython.
Düsseldorf Sprint Report 2010
This years installment of the yearly PyPy Düsseldorf Sprint is drawing to a close. As usual, we worked in the seminar room of the programming language group at the University of Düsseldorf. The sprint was different from previous ones in that we had fewer people than usual and many actually live in Düsseldorf all the time.
David spent the sprint working on the arm-backend branch, which is adding an ARM backend to the JIT. With the help of Armin he added support for bridges in the JIT and generally implemented missing operations, mostly for handling integers so far.
Ronny and Anto worked the whole week trying to come up with a scheme for importing PyPy's SVN history into a mercurial repository without loosing too much information. This is a non-trivial task, because PyPy's history is gnarly. We are nearly at revision 79000 and when we started using it, Subversion was at version 0.1. All possible and impossible ways to mangle and mistreat a Subversion repository have been applied to PyPy's repo, so most of the importing tools just give up. Ronny and Anto came up with a new plan and new helper scripts every day, only to then discover another corner case that they hadn't thought of. Now they might actually have a final plan (but they said that every day, so who knows?).
 The branch history of PyPy's repository (every box is a branch)
The branch history of PyPy's repository (every box is a branch)Carl Friedrich and Lukas started working in earnest on memory benchmarks to understand the memory behaviour of Python code better. They have now implemented a generic memory benchmark runner and a simple analysis that walks all objects and collects size information about them. They also added some benchmarks that were proposed in the comments of the recent call for benchmarks. As soon as some results from that work are there, we will post about them.
There were also some minor tasks performed during the sprint. Armin implemented the _bisect module and the dict.popitem method in RPython. Armin and Carl Friedrich made the new memory-saving mapdict implementation more suitable to use without the JIT (blog post should come about that too, at some point). They also made classes with custom metaclasses a lot faster when the JIT is used.
The last three days of the sprint were spent working on Håkan's jit-unroll-loops branch. The branch is meant to move loop invariants out of the loop, using techniques very similar to what is described in the recent post on escape analysis across loop boundaries (see? it will soon stop being science-fiction). Some of the ideas of this approach also come from LuaJIT which also uses very aggressive loop invariant code motion in its optimizers. Moving loop invariants outside of the loop is very useful, because many of the lookups that Python programs do in loops are loop invariants. An example is if you call a function in a loop: The global lookup can often be done only once.
This branch fundamentally changes some of the core assumptions of the JIT, so it is a huge amount of work to make it fit with all the other parts and to adapt all tests. That work is now nearly done, some failing tests remain. The next steps are to fix them and then do additional tests with the translated executable and look at the benchmarks.
It's great to see improvements in pypy. At this moment, the only three benchmarks that perform better in cpython than in pypy are spitfire, slow spitfire and twisted_tcp.
What's the reason for the lower performance on these benchmarks? Is it the same reason for the three or there are multiple causes?
Luis
Hey.
spitfire and slowspitfire are a 'won't fix' benchmarks (at least in the near future). The spitfire_cstringio is using the same thing, but cStringIO instead of a list of strings.
Twisted_tcp is slightly more complex and has something to do with pushing a lot of data through sockets. In pypy you usually have to copy data before write, because it can potentially be moved in the GC.
Cheers,
fijal
Thanks! I suppose "won't fix" has a meaning in a pypy context. What does it mean?
won't fix means we won't fix it ;-) To be precise it means we know this program is slow, but also there is a way to write this program to be fast, please use the other way.
So it doesn't make much sense including these benchmarks in speed.pypy.org, don't you think?
Perhaps it should be described somewhere what are the strengths and weaknesses of this implementation, suggesting the right approach for each task. Something like "best practices" or something like that...
I think deleting it from the nightly run doesn't make sense. It still measures something and helps us catch regressions.
The document you're proposing is actually a really neat idea. I've already did a couple of presentation on it, so it's only about gathering knowledge ("only").
Armin,
Don't forget to ping pypy-sprint about this to avoid people getting confused again ;)
Victor: sorry, I don't get you. Do you mean, to tell people about the updates I did to the blog post? Or just to send the announcement to pypy-sprint too (I only sent it to pypy-dev so far)?
I meant just to send the announcement to pypy-sprint too. IIRC, someone looked there for the last sprint and got confused by the announcement of a sprint in the same month of last year.